操作指导手册
虎符操作指导
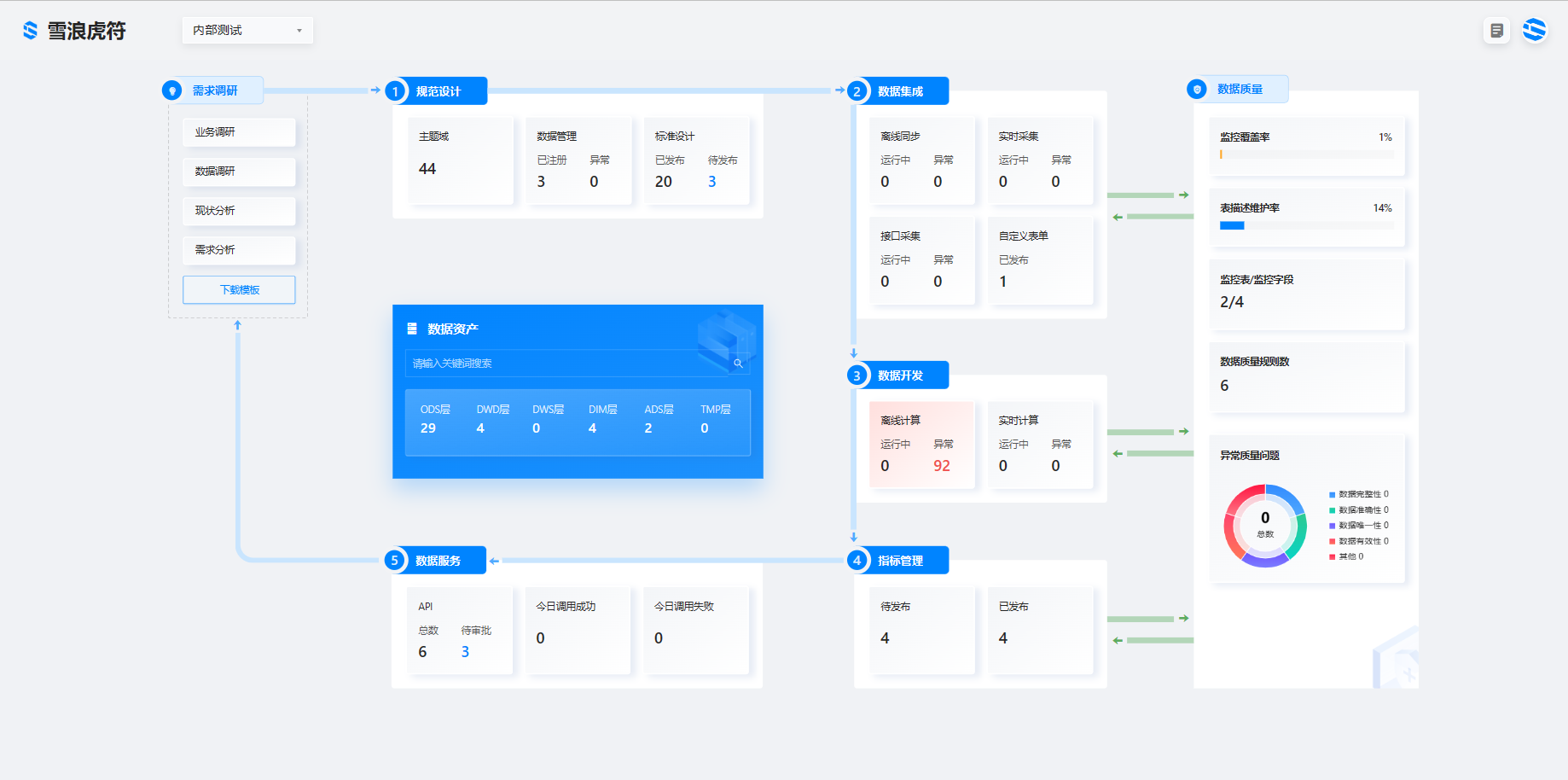
场景分类:
一、基于生产管理业务系统(MES)数据的集成开发
1.将 MES 中的数据源注册至虎符
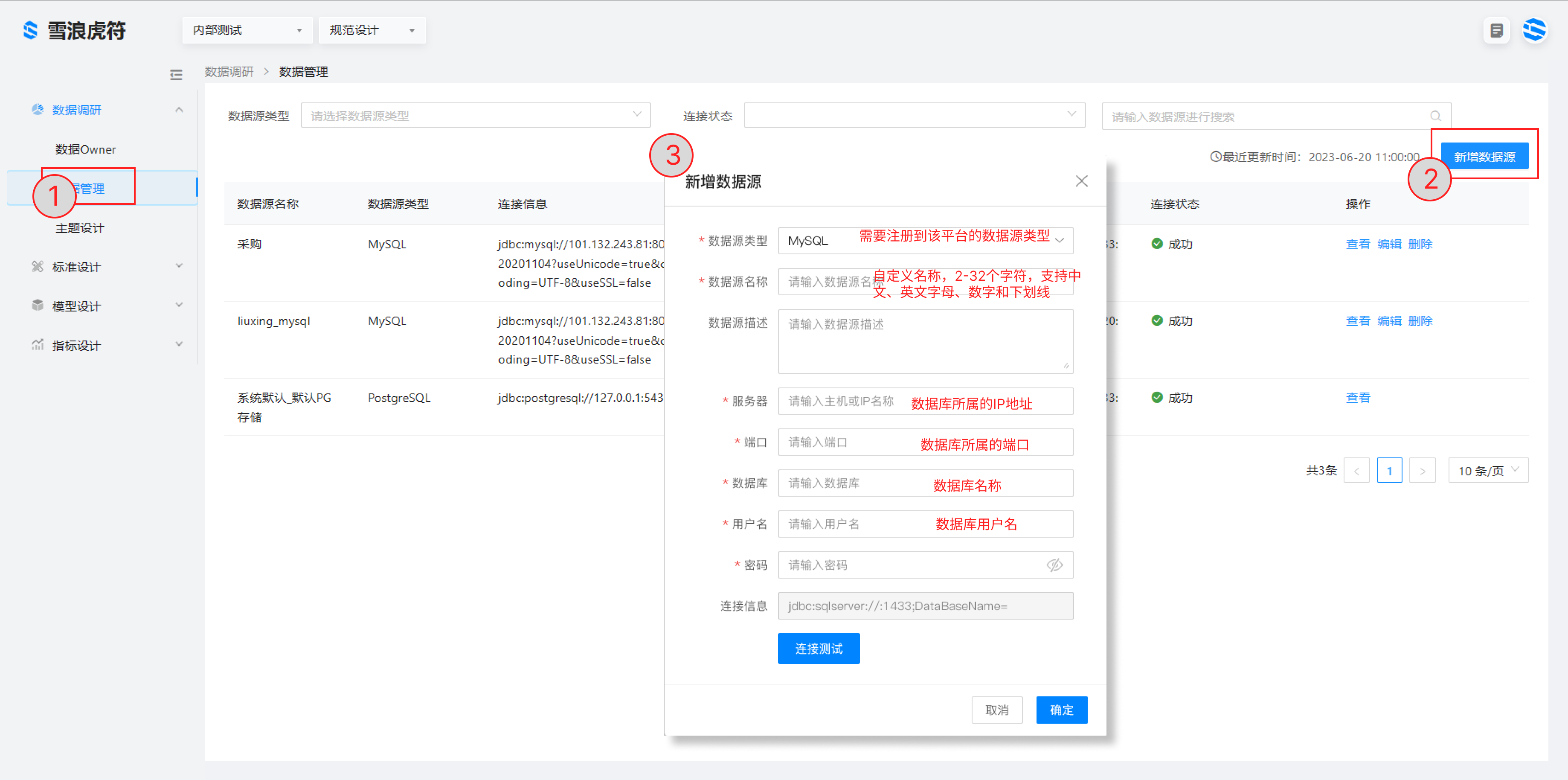
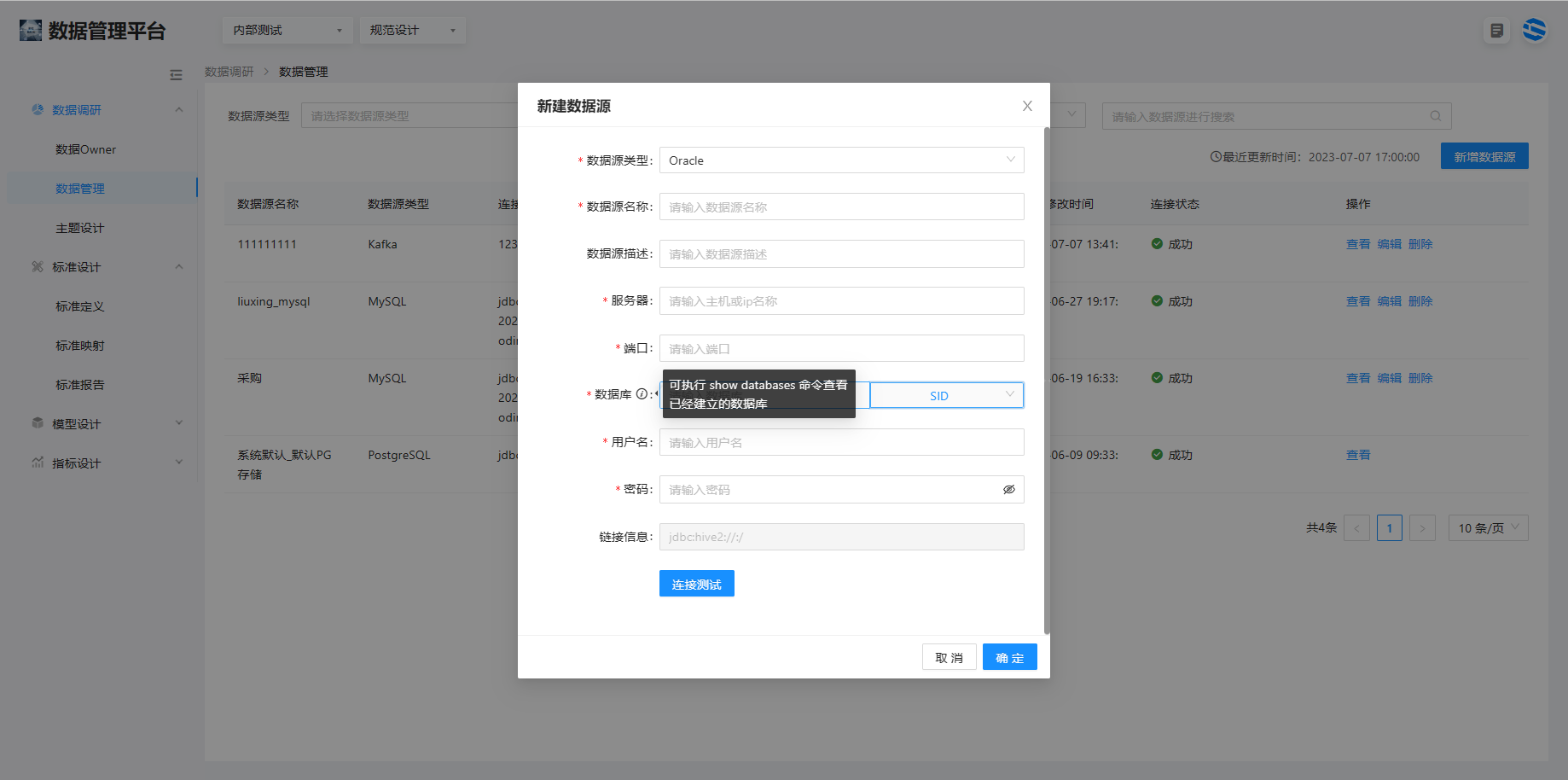
1.1 关系型数据库(MySQL、Oracle)的注册
选择规范设计 > 数据调研 > 数据管理单击右上角新建数据源配置各项参数。数据源名称可命名为业务系统名称 + 数据源类型:MES_MySQL
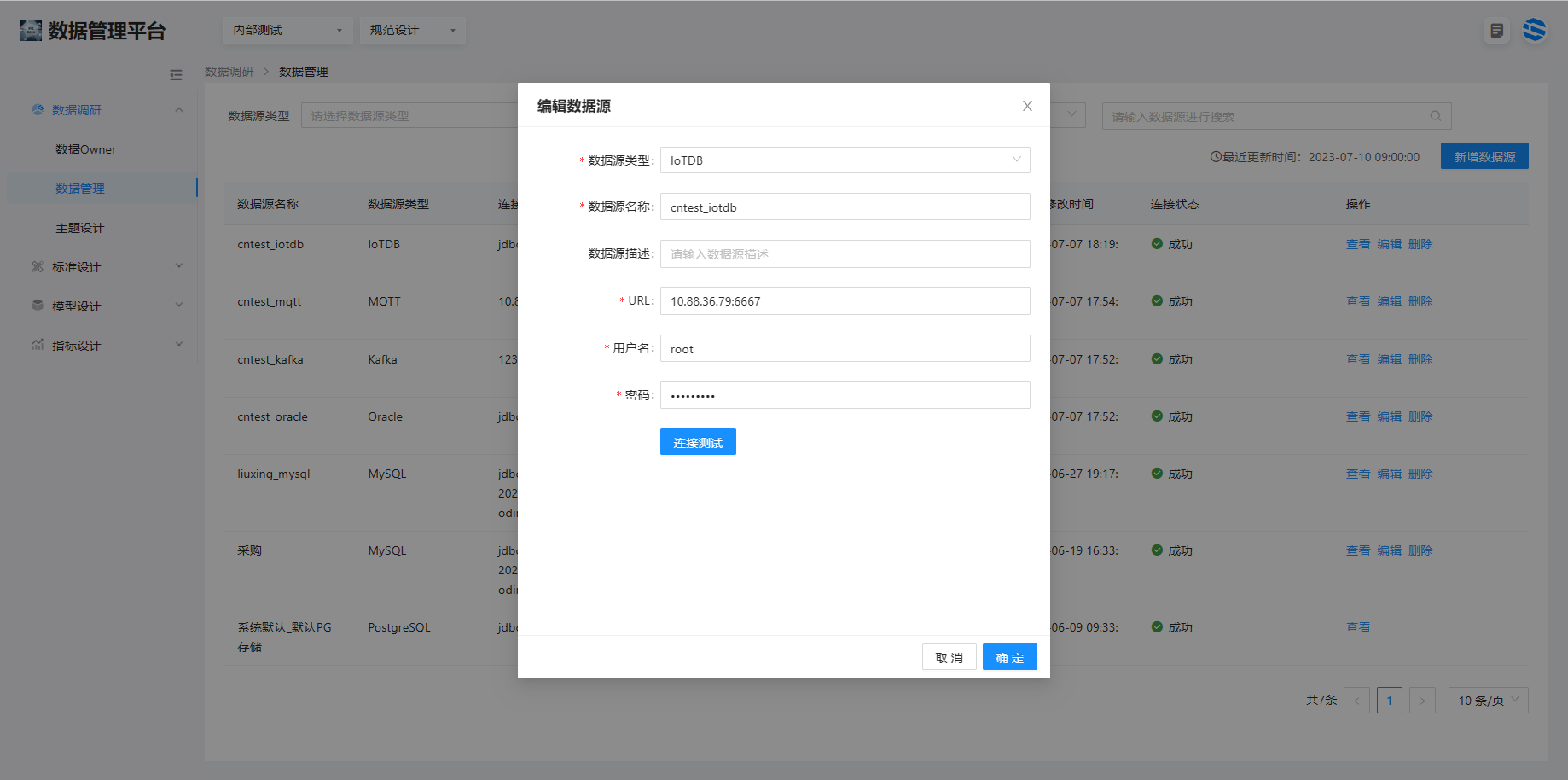
1.2 时序数据库(IoTDB)的注册
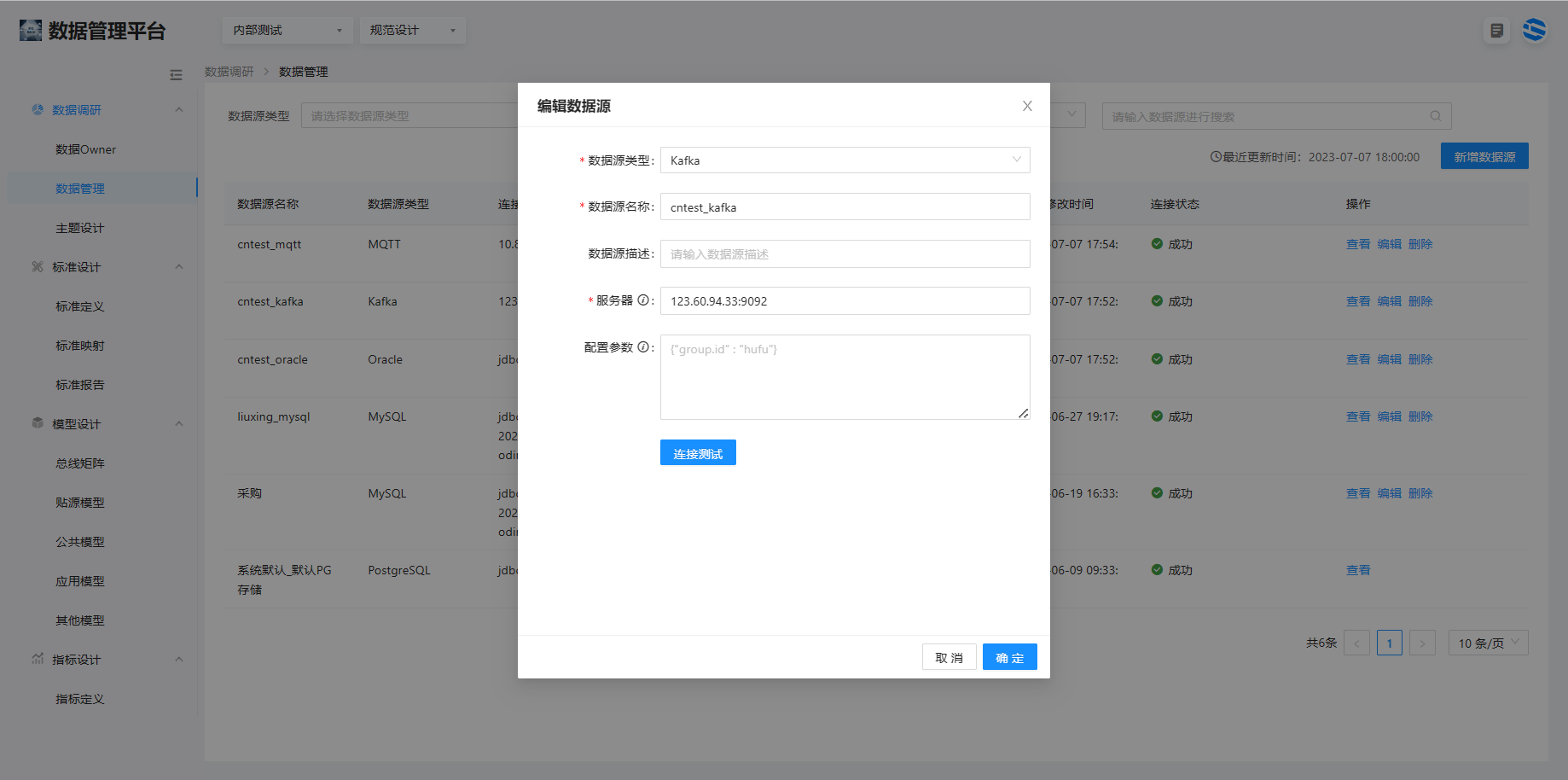
1.3 消息队列系统(Kafka)的注册
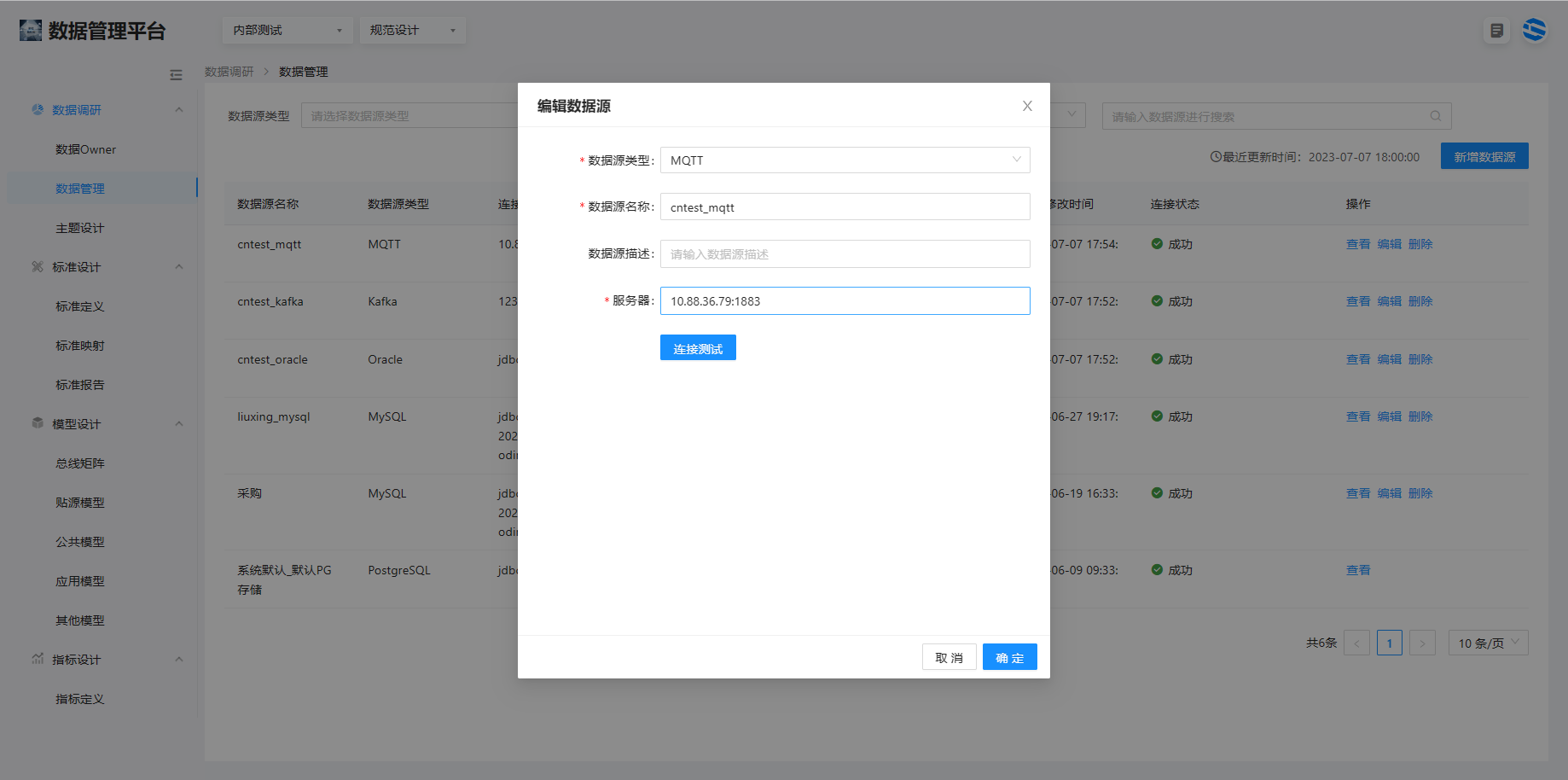
1.4 通信协议(MQTT)的注册
2.构建生产主题域的数据模型
操作步骤:
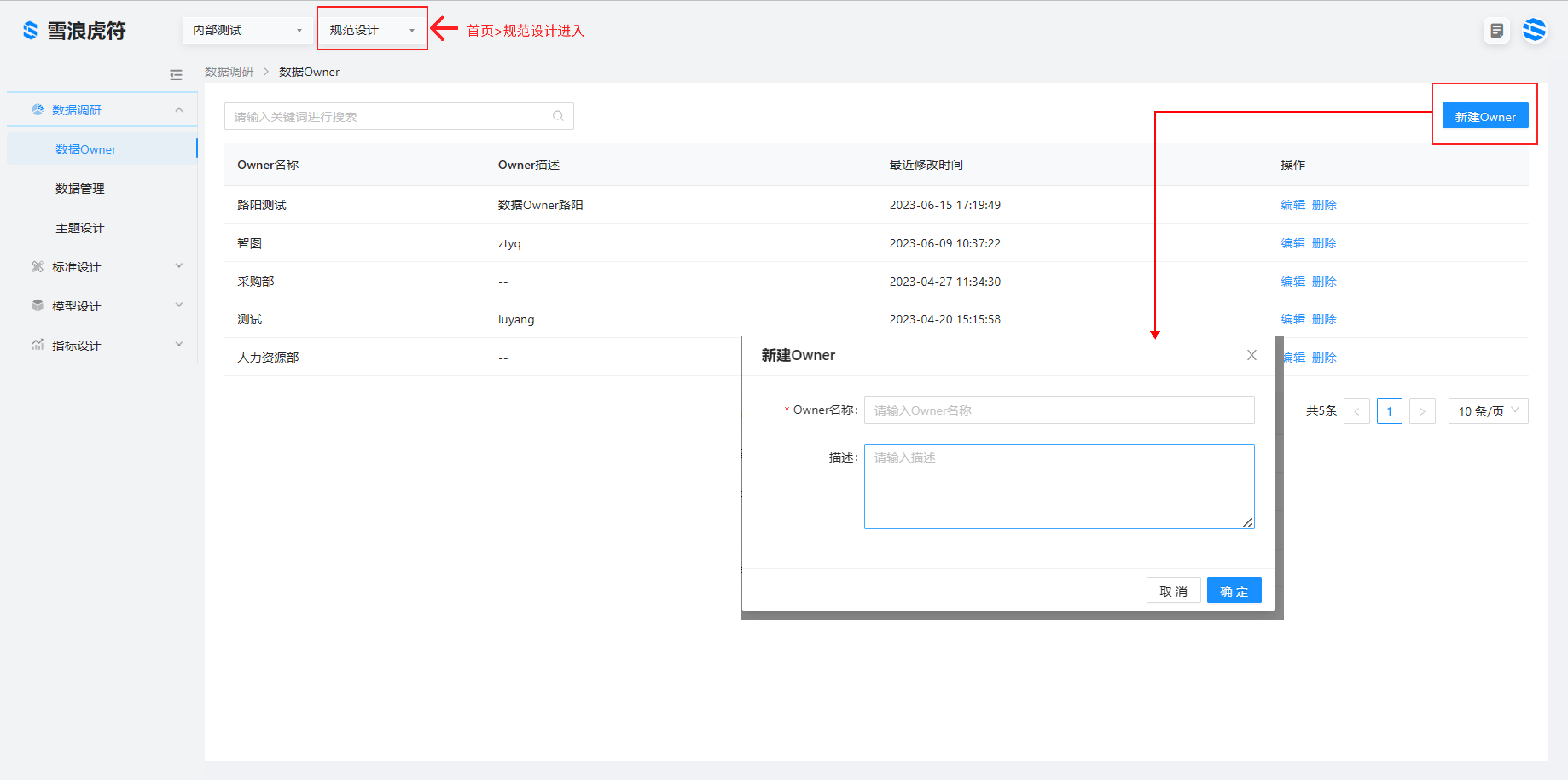
1、确定生产域数据 owner
虎符首页 >规范设计>新建数据 owner配置 owner 参数(Owner 名称可以为个人或者部门。)owner 名称写生产部或者生产管理员
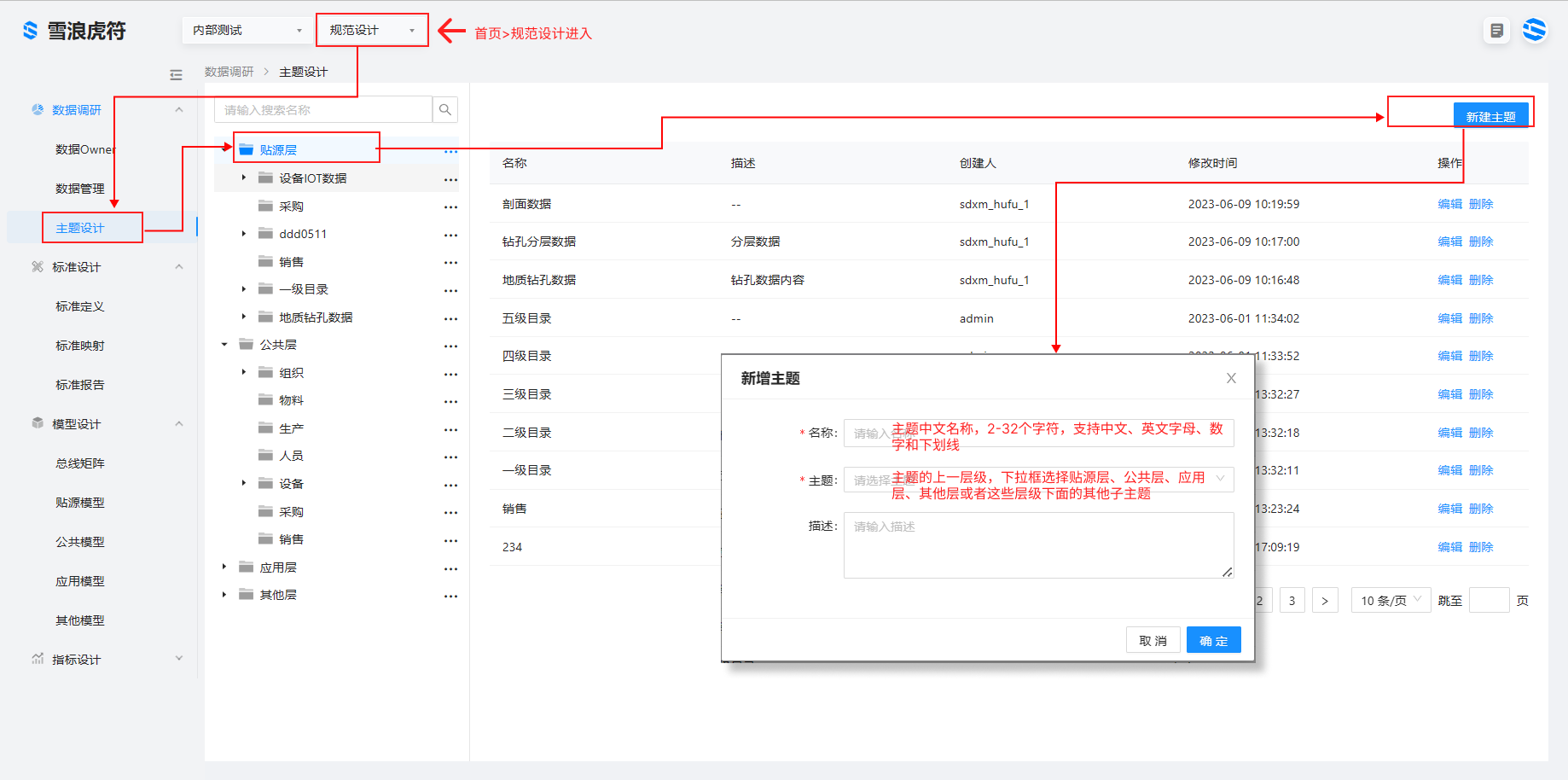
2、进行生产主题设计。
规范设计>数据调研>主题设计主题设计用于设计分层架构表达对数据的分类和定义。默认分为四层,分别是:贴源层、公共层、应用层、其他层
贴源层:存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主题设计主要围绕数据来源展开,例如 MES 系统、ERP 系统等。
公共层:又称通用数据模型层,包括 DIM 维度表、DWD 和 DWS,由 ODS 层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。主题设计主要围绕业务属性展开,如生产、质量、销售、物流等。
应用层:存放数据产品个性化的统计指标数据。主题设计主要围绕应用展开,如 BI、大屏、app 等。
其他层:存放数据临时性模型与不符合数仓规范的模型,主题设计不做特殊要求。
a、选择贴源层,新建MES主题,主题选择贴源层;
b、选择公共层,新建主题-生产,点击新建主题,新建生产订单和计划,主题选择公共层-生产,点击确认。依前面描述步骤,在生产主题里新建生产过程监控、质量管理等子主题
c、应用层,新建每日生产产量看板
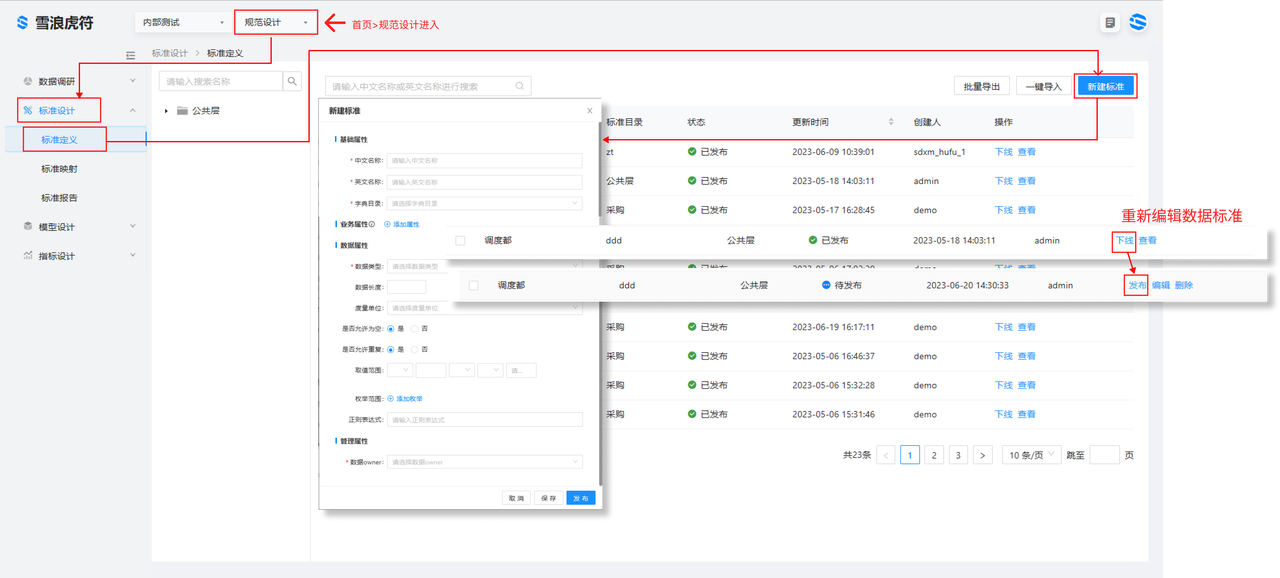
3、标准定义,明确标准的各类属性。
选择标准设计>标准定义> 点击右上角新建标准,进入标准弹窗配置各项参数。
例如:生产中实际生产量字段,在弹窗里依次填入中文名称、英文名称、字典目录下拉框选择生产、数据类型:字符型,数据 owner:生产部。
4、进行生产主题模型设计。
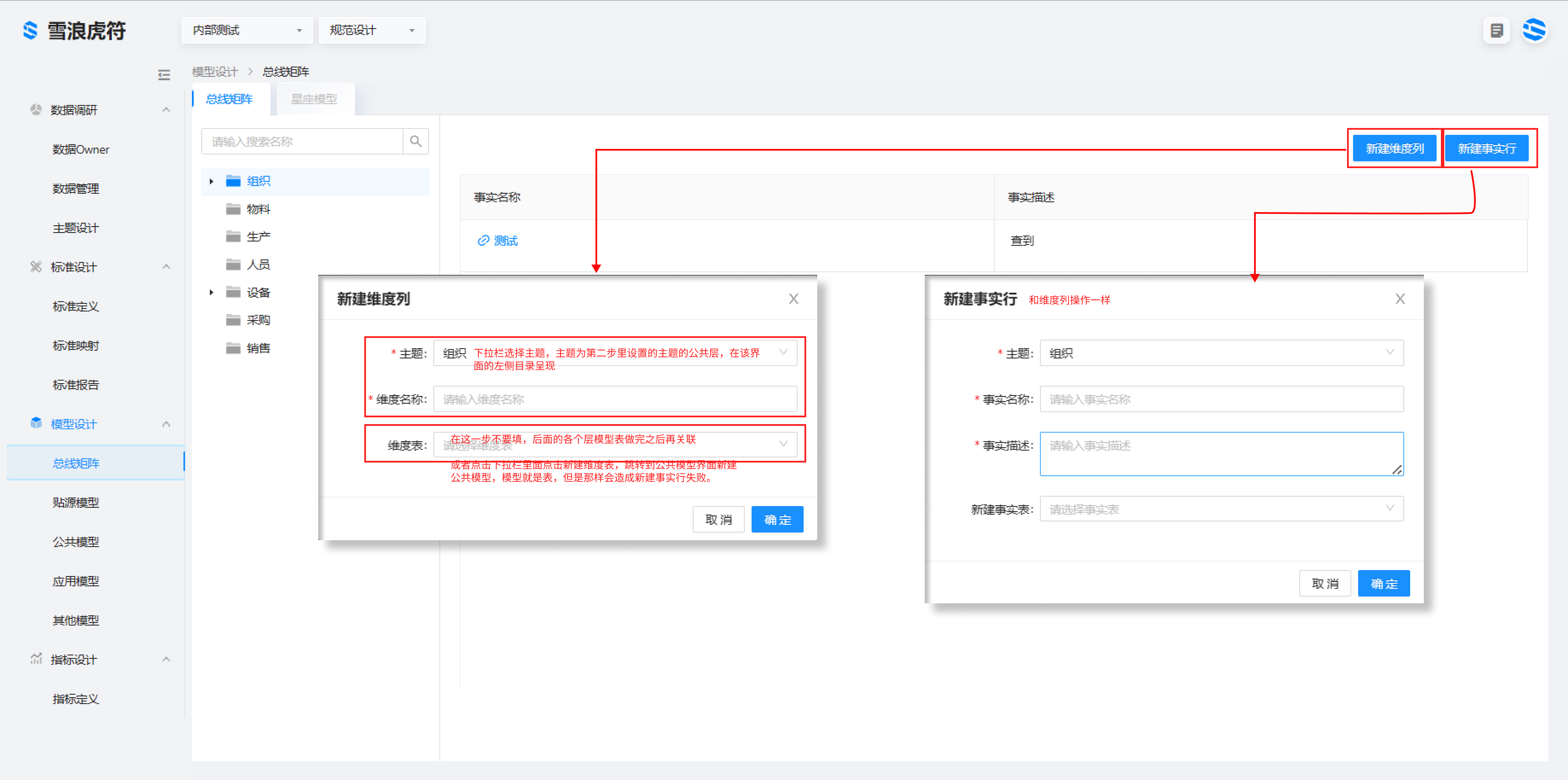
模型设计是一个总分框架。总线矩阵是对企业数仓规划设计的一种方式,行是业务过程,列是公共维度;通过总线矩阵,可以对整个数仓的结构有一个清晰的了解,能够看出某个业务过程包含哪些通用维度。通过总线矩阵建设数据结构框架,可以处理不同的以过程为中心的维度模型的实现,且他们的实现严格遵守一致性维度。
4.1 构建总线矩阵,模型框架
总线矩阵通过创建事实行与维度列,通过构建行列之间的关系完成总线矩阵的设计。事实行与维度列需要连接不同的维度表和事实表。这些表是处于不同层的模型。
1.选择规范设计 > 模型设计 > 总线矩阵 > 新建事实行进入事实行编辑页面,新建工单执行事实,先不要关联事实表
2.模型设计 > 总线矩阵 > 新建维度列进入维度列编辑页面,新建产线维度,先不要关联维度表,依此新建时间维度、产品维度、销售地址维度
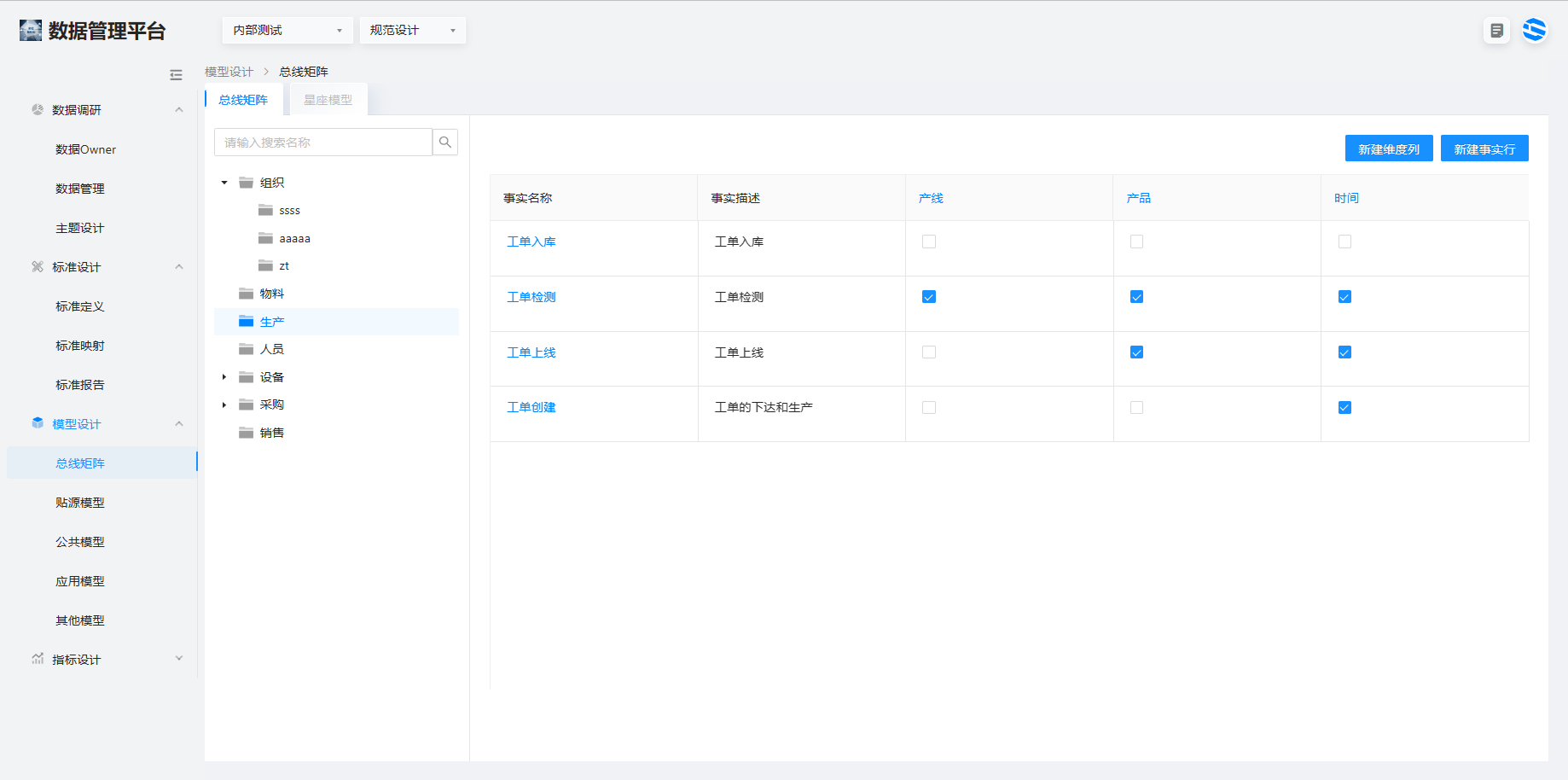
4.2 构建业务关系
在构建好事实行和维度列以后,在总线矩阵页面。将行列之间的业务关系进行打勾关联(✅)。
4.3 构建逻辑关系
1、选择公共模型 > 新建公共模型,注意公共模型里有 dwd、dws 和 dim 三个层
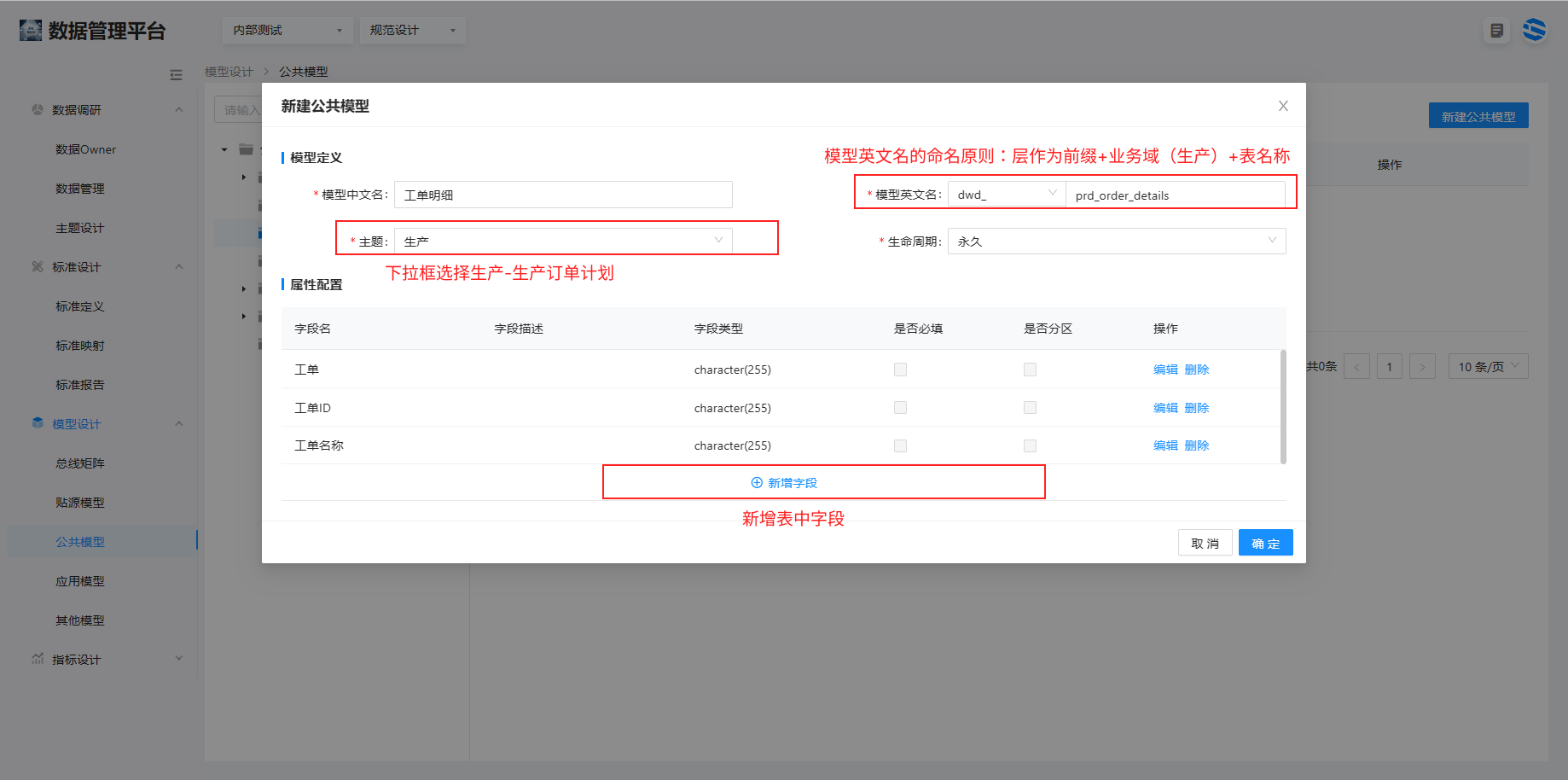
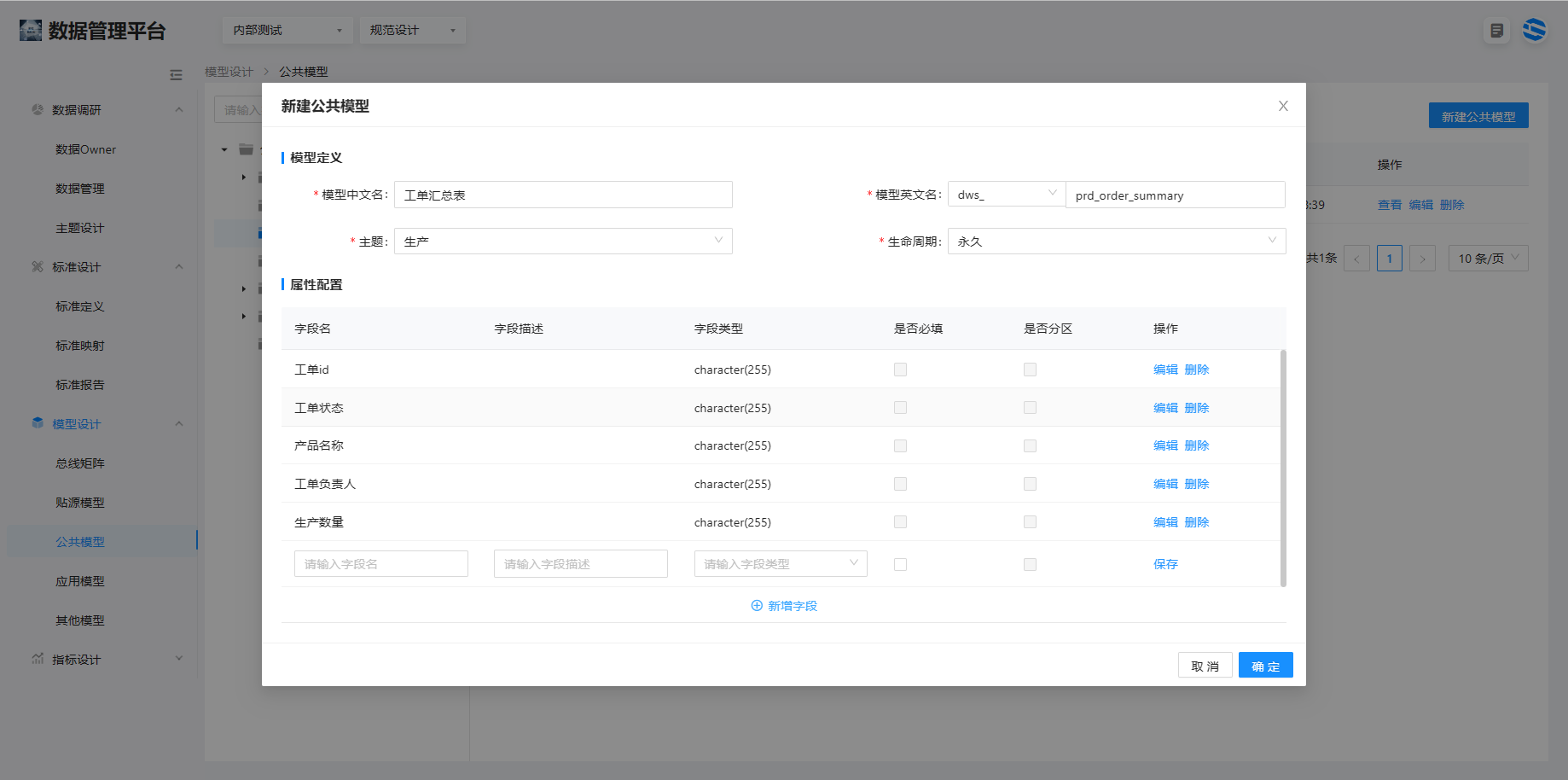
如图所示新建公共层 dws 表
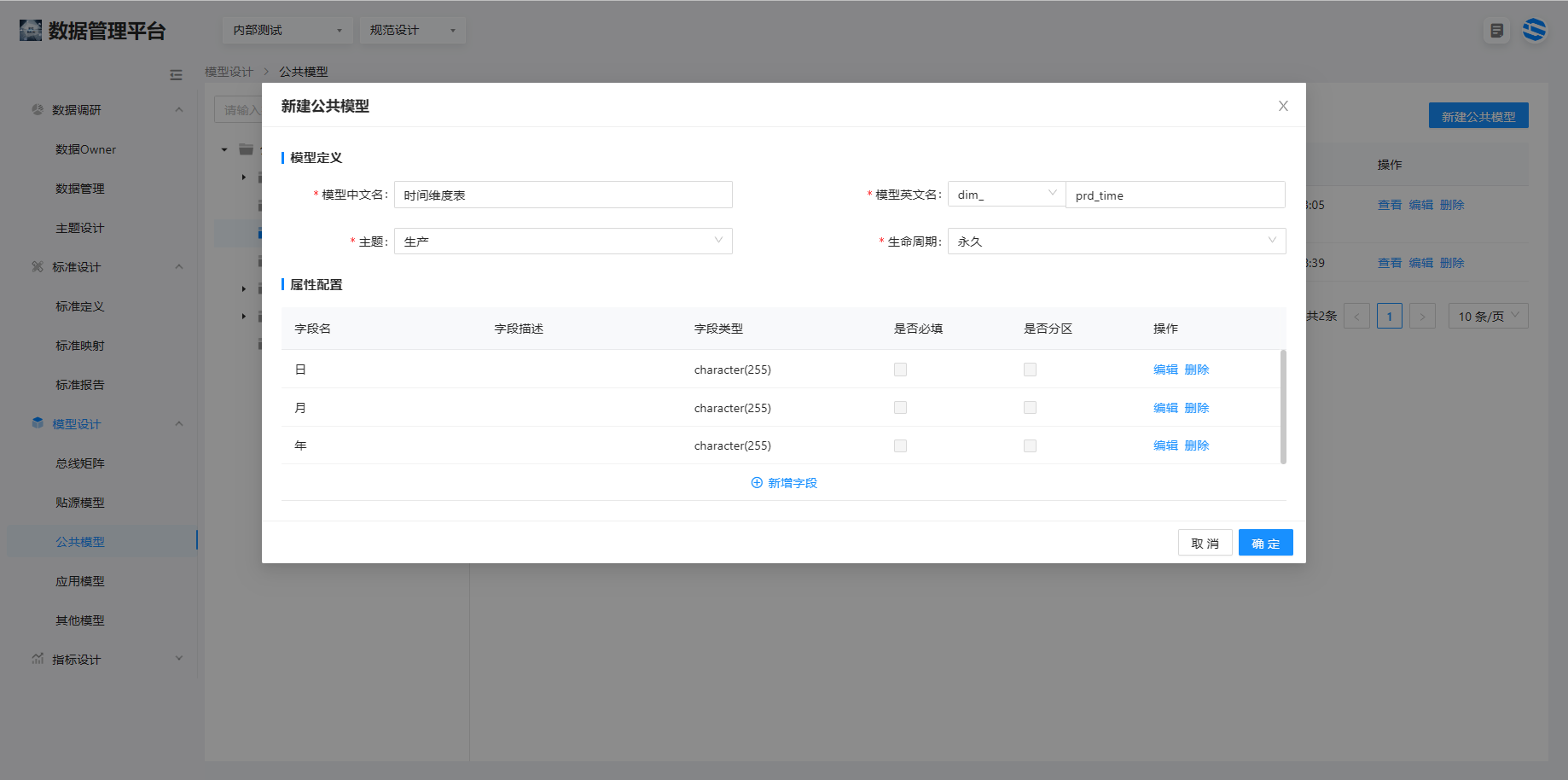
如图所示新建公共层 dim 表
6、新建应用模型和其他模型
7、选择总线矩阵 > 单击“工单上线”事实行 >进入编辑事实行页面 > 点击新建事实表,下拉框选择对应的事实表 dws_prd_order_summary
单击“时间”维度列 >进入编辑维度列页面 > 点击新建维度表,下拉框选择对应的维度表 dim_prd_time每个事实行与维度列都可以绑定一张数据表,用于构建逻辑关系,单击行或者列出现表关联,关联之后会出现链接标识,则代表关联成功(🔗)。

3.对各类数据进行数据集成
3.1 数据(数据库)的离线集成
根据业务需求选择离线同步或者实时同步
3.1.1 全量数据的离线同步:
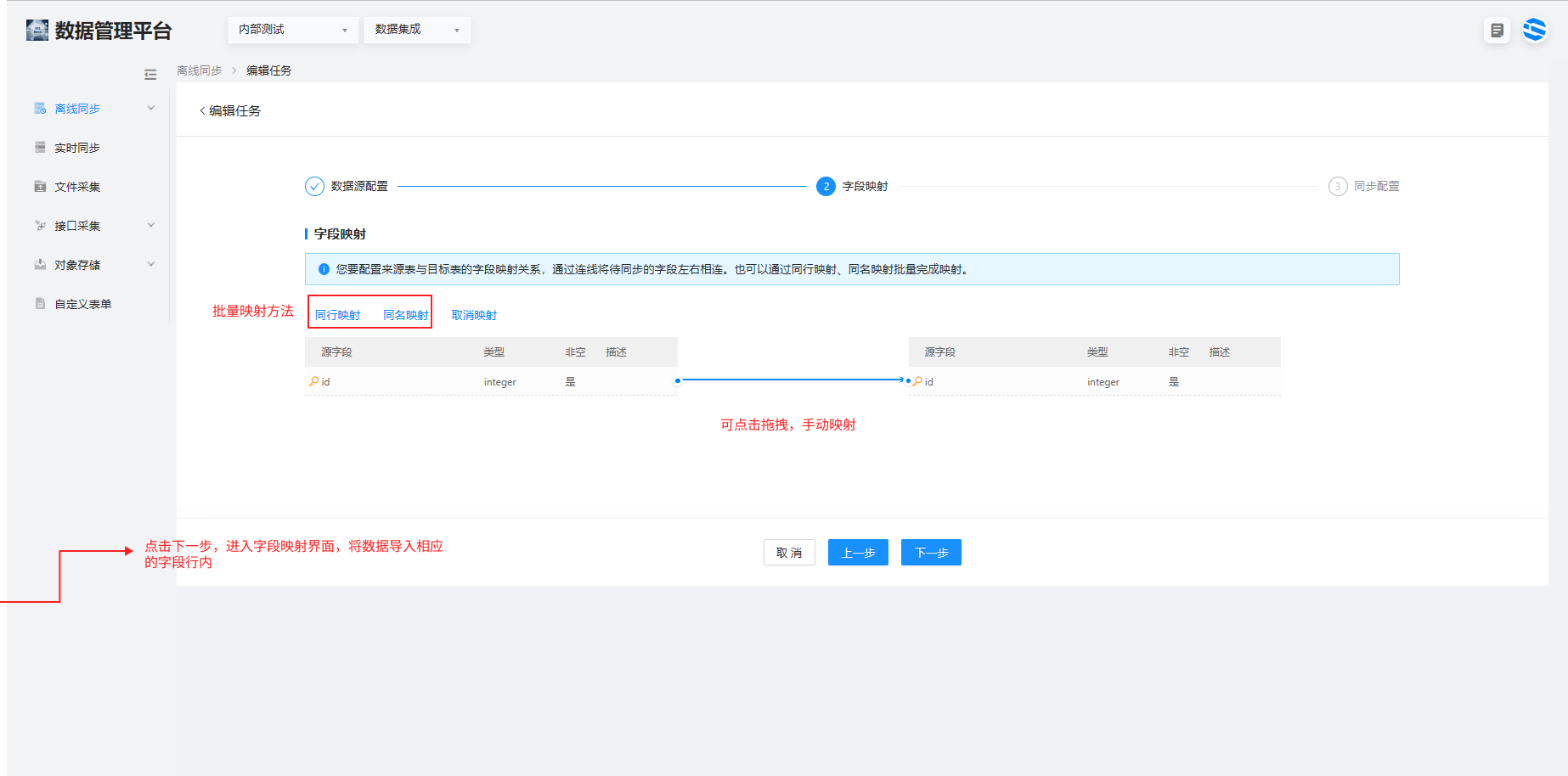
1.选择数据集成>离线同步 >单击右上角的新建离线任务,进入任务编辑界面进行数据源配置、字段映射和同步配置。
数据源配置:任务名称根据本次导入的数据起名称:p-suppliers 表同步;目录选择符合数据主题的目录:MES 系统数据同步。
数据目标选择系统默认数据源,选择目录,选择目标表(此目标表是在模型设计中各个层的表),贴源层的表可以通过一键建表的方式建成。
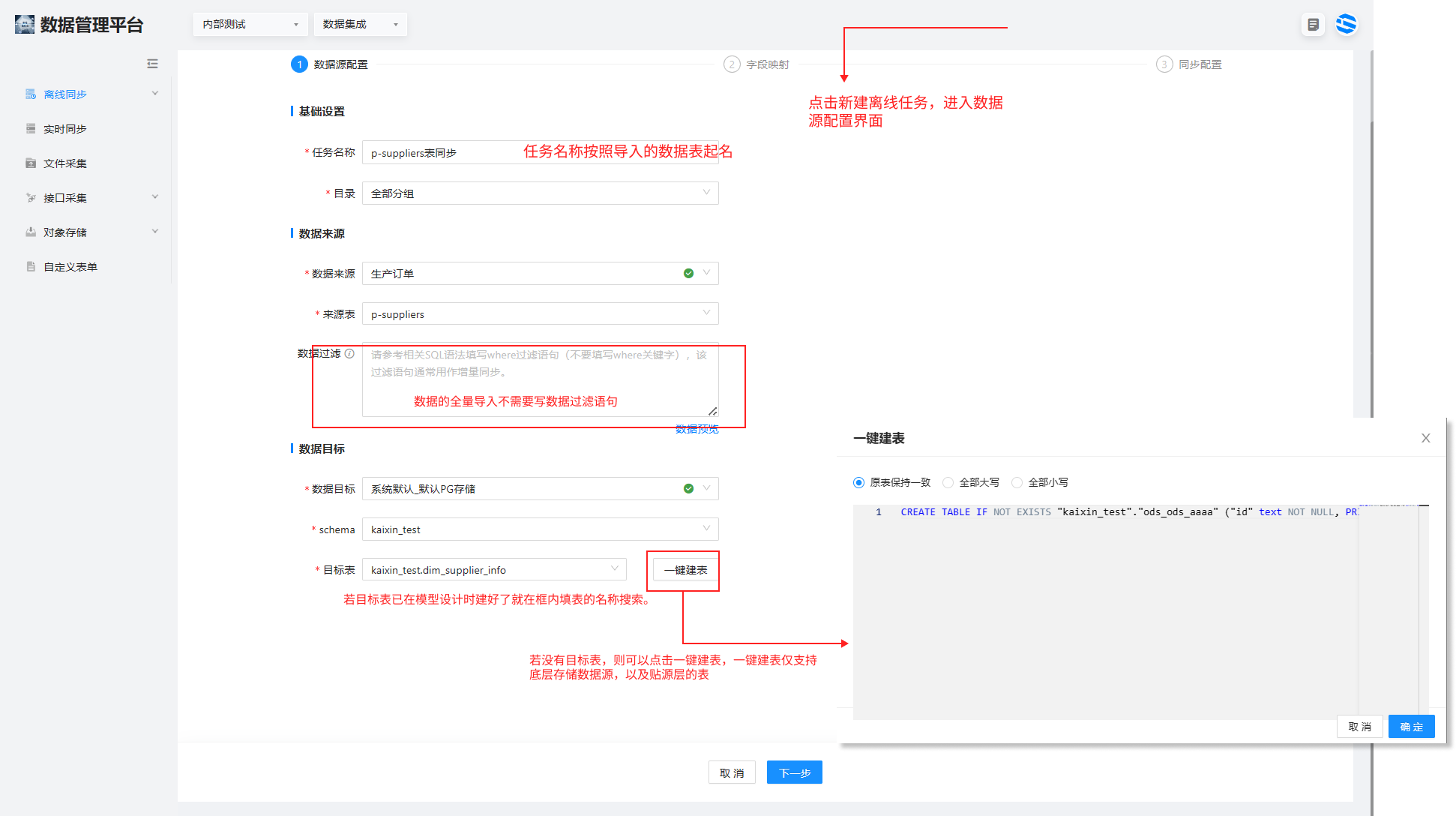
确定数据的导入位置。可选择同名映射或同行映射的批量快捷映射方法,也可以手动拖拽实现字段的映射。
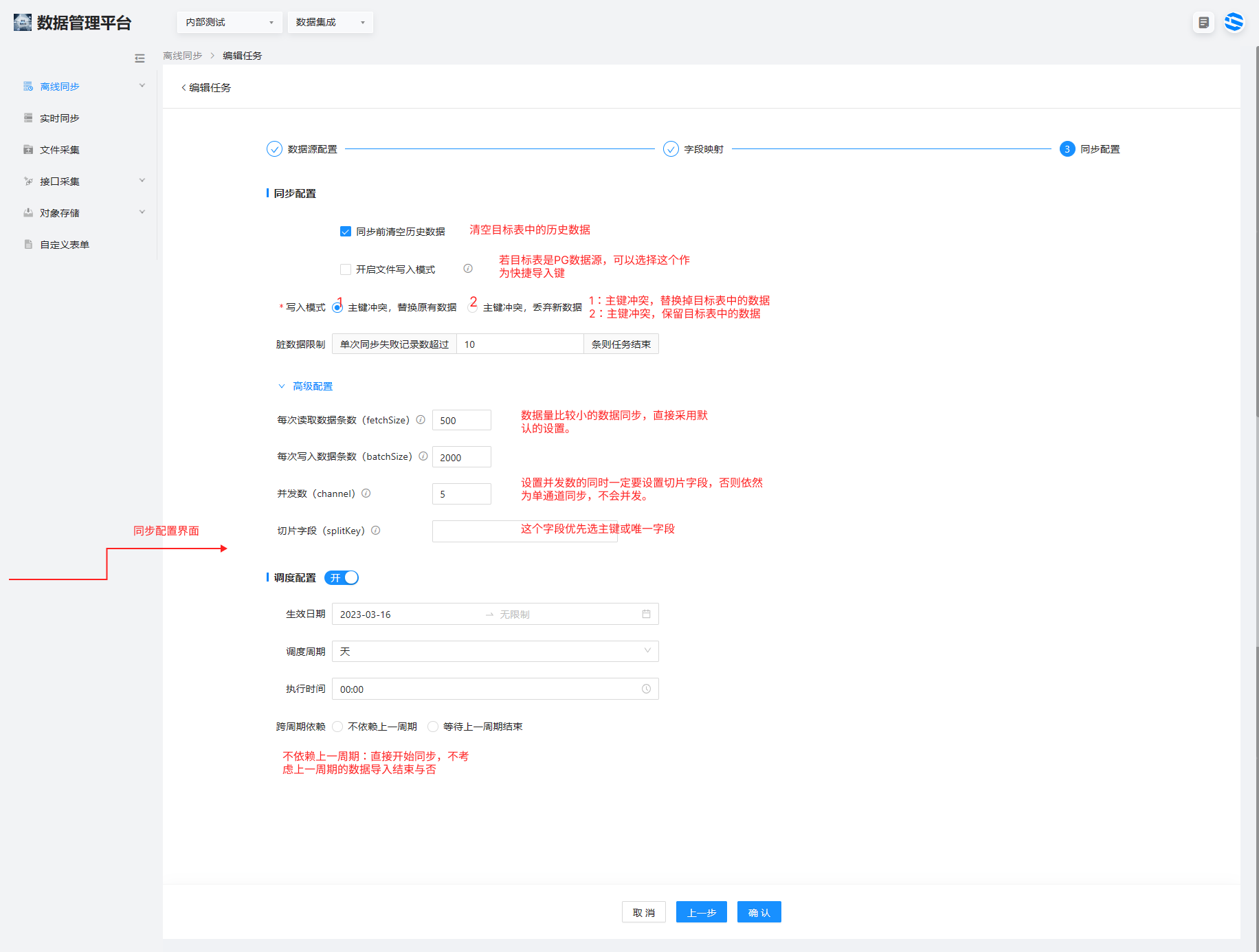
同步配置:
同步配置,第一次全量数据同步,可选择“同步前清空历史数据”,确保目标表没有无关数据。
写入模式可选择替代目标表中的数据或者保留目标表中的数据。
3.1.2 增量数据的离线同步:
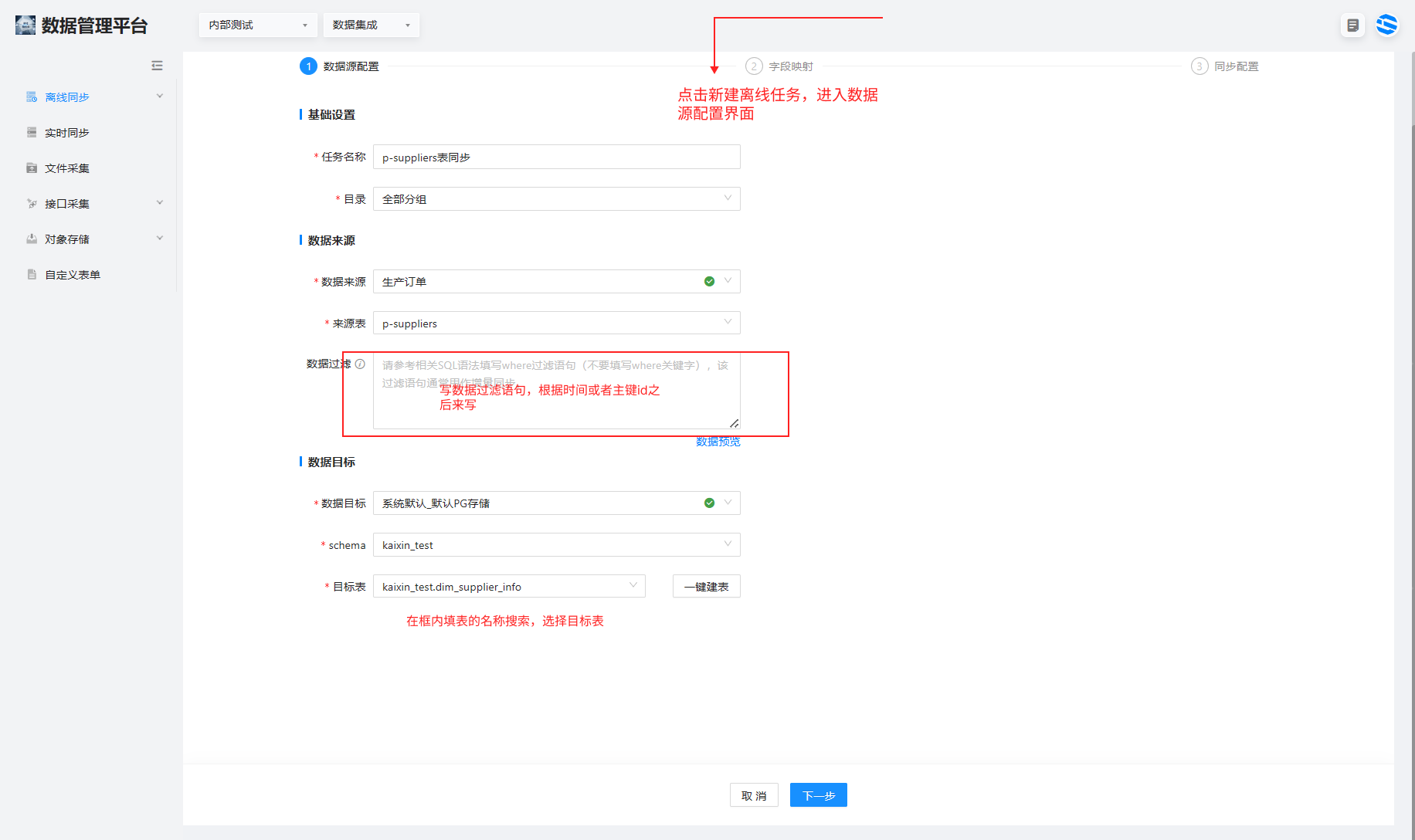
选择数据集成>离线同步 >单击右上角的新建离线任务,进入任务编辑界面进行数据源配置、字段映射和同步配置。
1.数据过滤语句,根据时间戳在某时间之后的数据或者某 id 之后的数据开始导入。
SELECT *
FROM p-suppliers
WHERE ID > (SELECT MAX(ID) FROM kaixin_test.dim_supplier_info);
在目标表框内输入之前创建的目标表名称并选择。
2.字段映射,选择同名或同行映射。
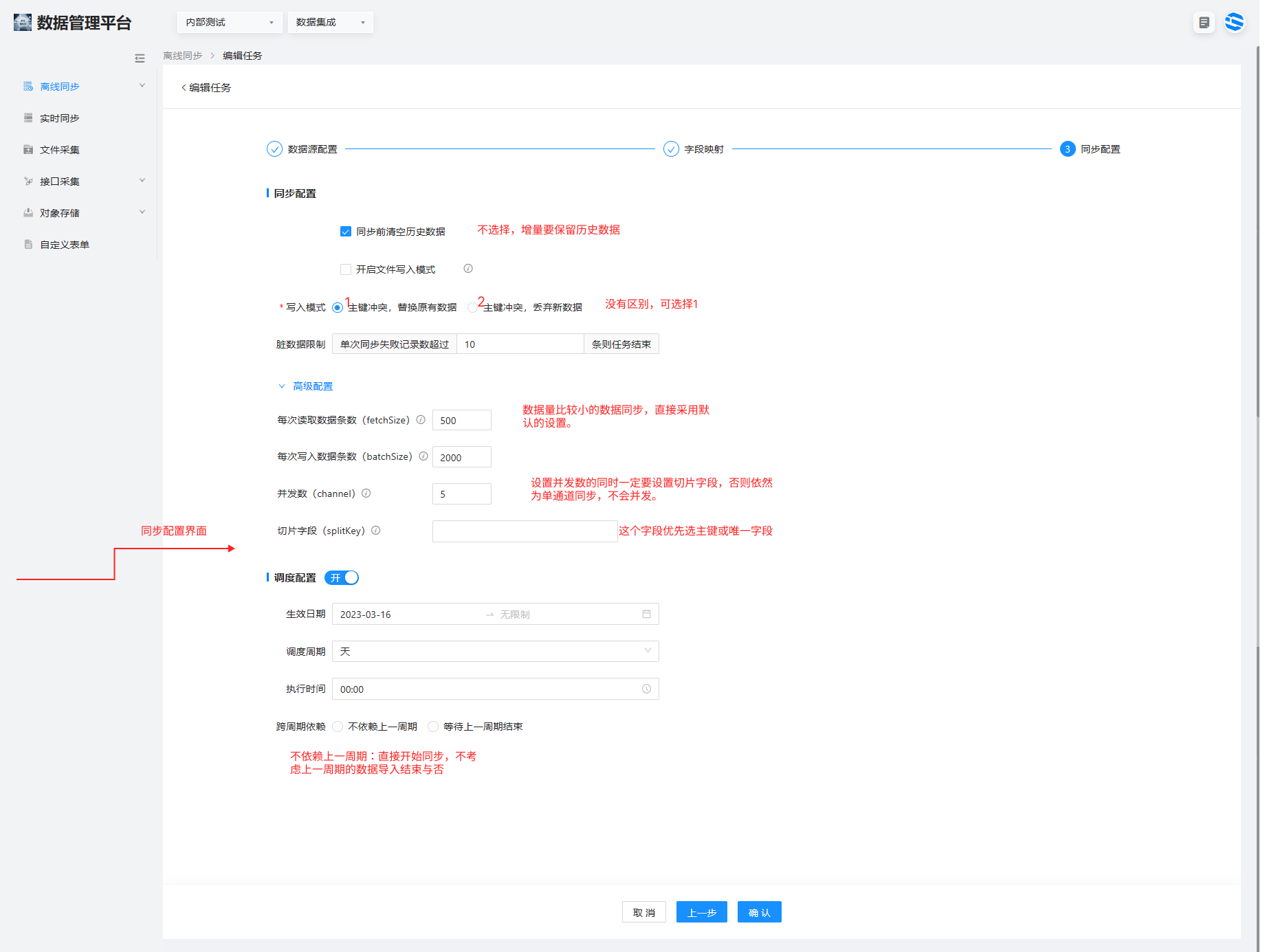
3.同步配置:
因为是增量同步,所以目标表中的历史数据要保留,写入模式可选择“主键冲突,替换原有数据”
跨周期依赖:选择等待上一周期结束(数据过滤阶段用的是 id 增量)
3.2 数据的实时同步
实时同步通过简单的配置,达到数据秒级从源端到目标端的同步,为处理或分析流数据的程序构建数据流管道。
3.2.1 mysql,oracle(关系型数据库)实时同步至 pg。
数据源配置的基础设置部分和数据目标部分同离线同步。在数据来源部分采集起点按照业务需求选择不同的采集起点。
1、已经在规范设计>数据调研>数据管理里面注册过了 MySQL、oracle 数据源。
2、选择数据集成>实时同步>新建实时任务,进入任务编辑界面
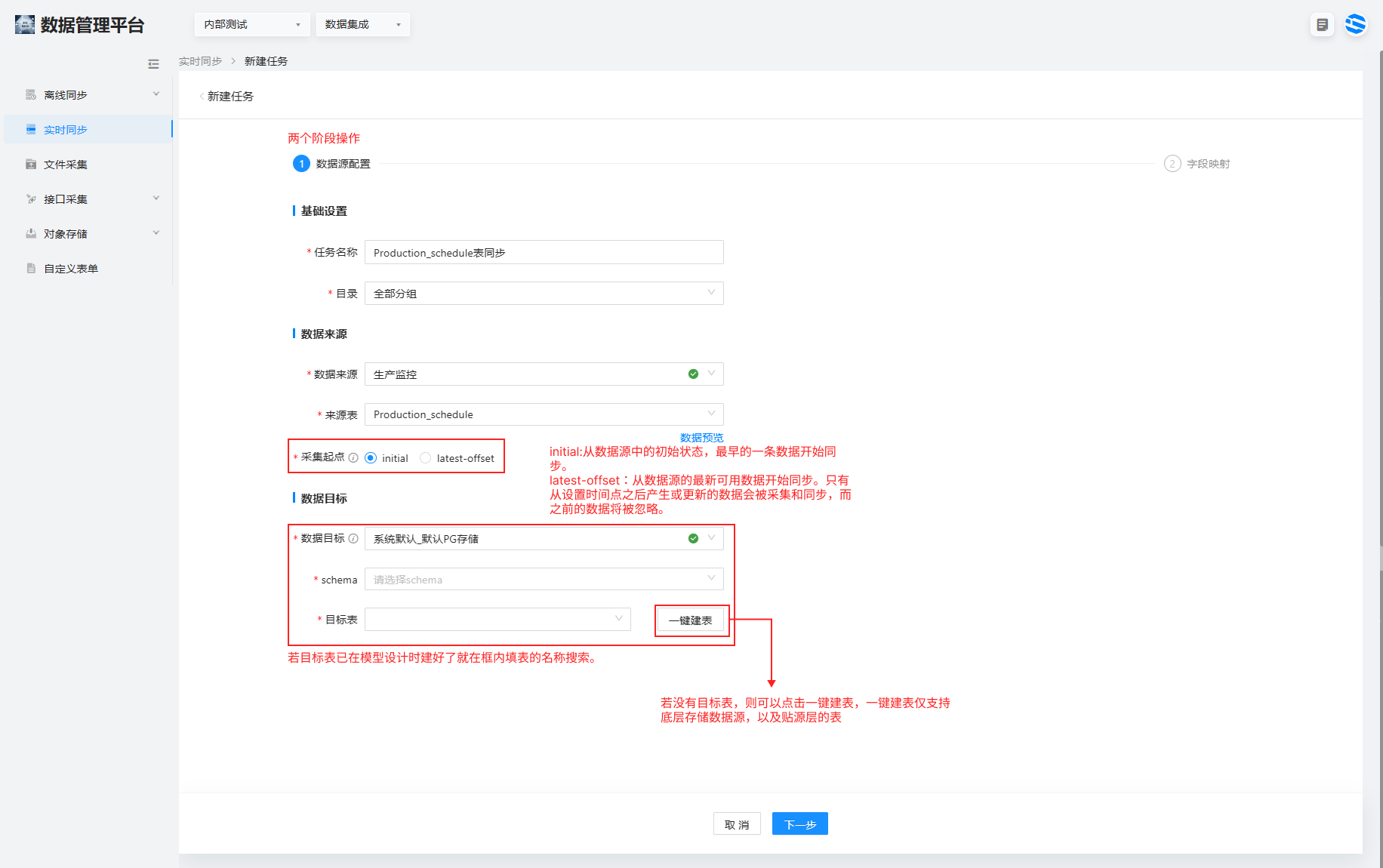
任务名称根据同步的表的名字起名称,填写 Production_schedule 表同步
数据来源:下拉框选择注册至虎符的 MySQL 数据源,下拉框选择要采集的数据表 Production_schedule。采集起点按数据的同步需要选择,可选择 latest-offset,历史数据采用离线同步的方式。
数据目标:选择默认存储数据源 pg,可选择一键建表
3.2.2 kafka,mqtt 怎么实时同步到 Iotdb
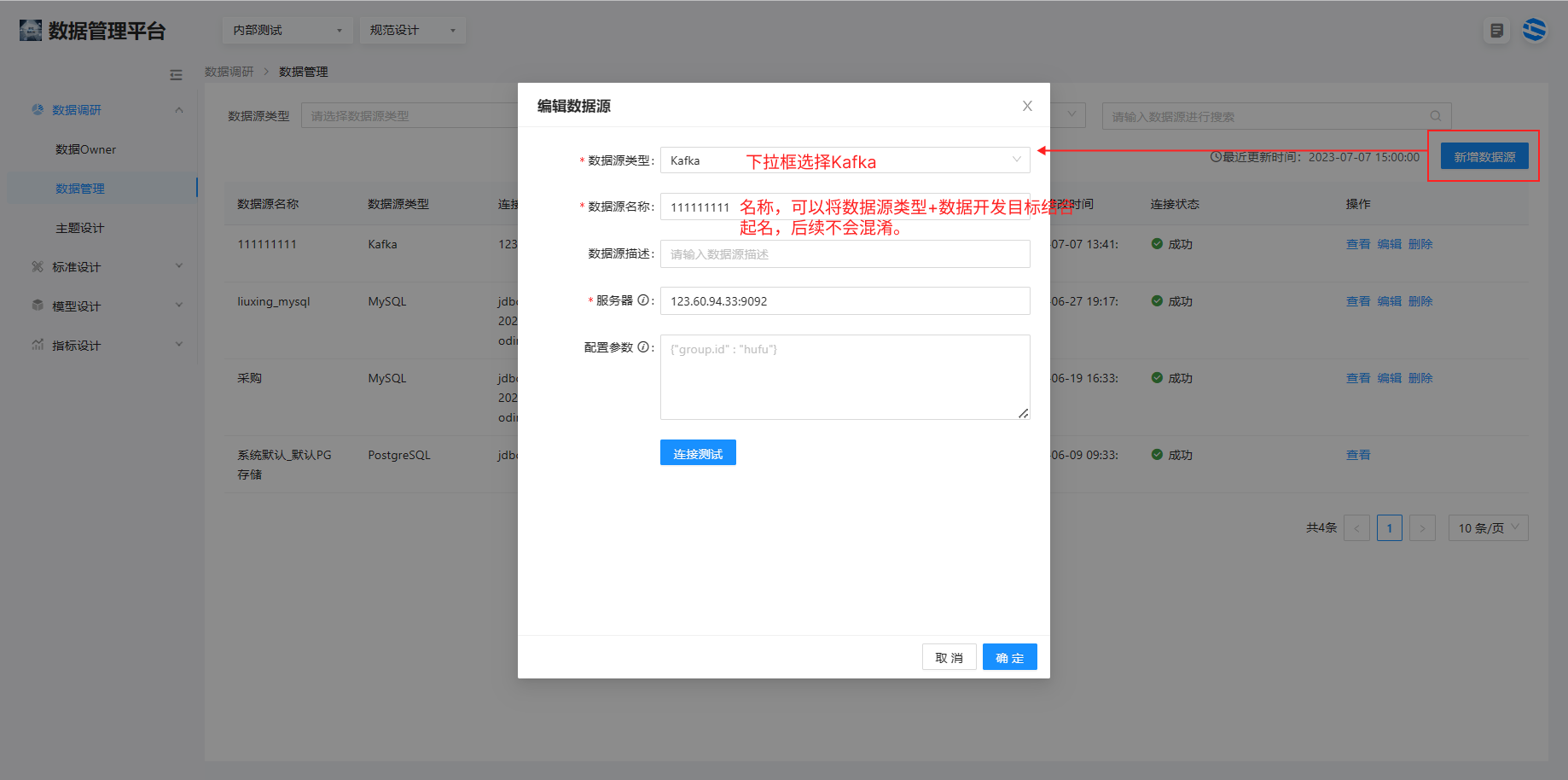
1、确定在规范设计 > 数据调研>数据管理> 右上角新增数据源,注册并连接成功了 Kafka、mqtt 数据源。
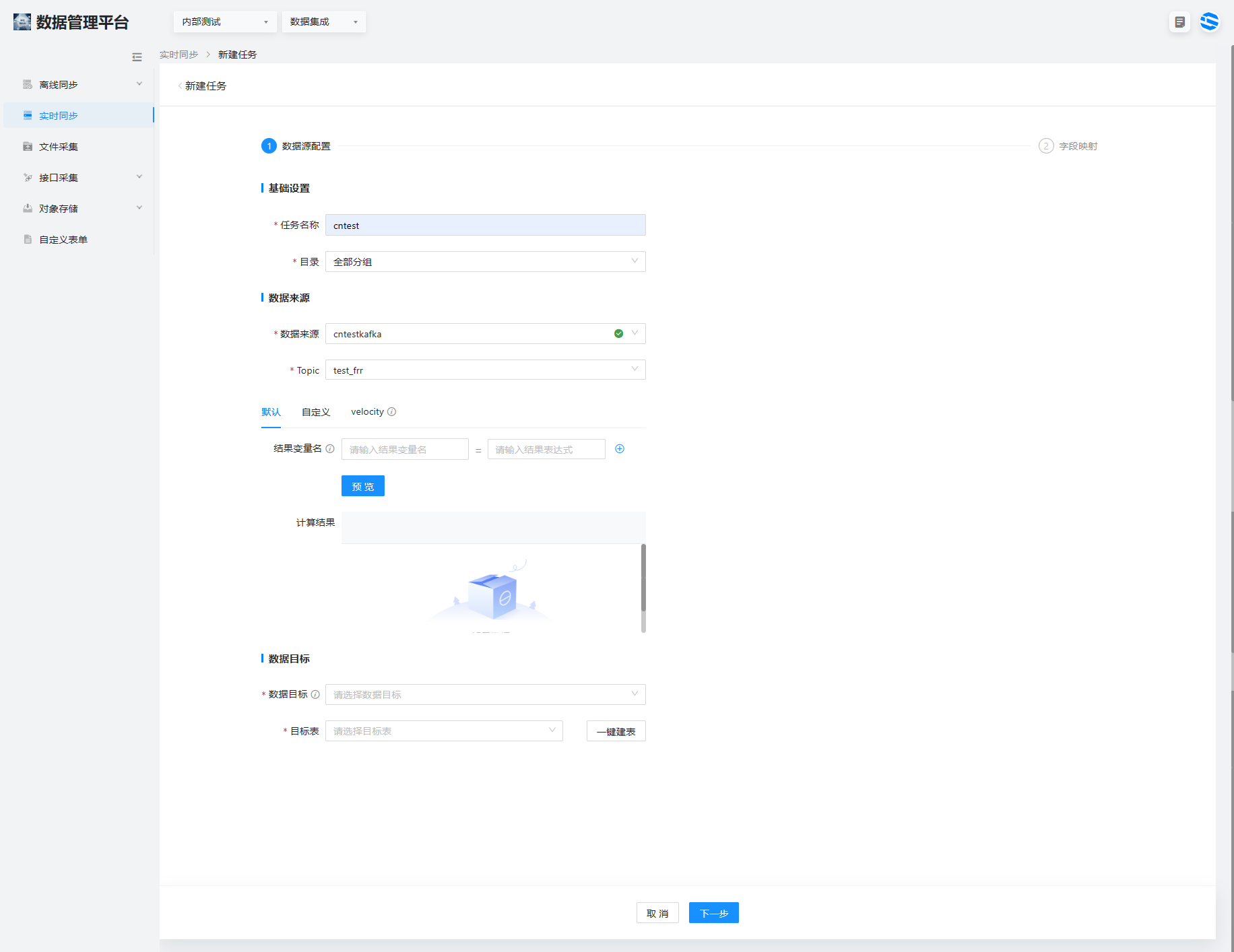
2、选择数据集成> 右上角新建实时任务,进入任务的编辑界面,数据来源和数据目标的配置
没有办法查看数据,所以在变量名那写什么?
3、选择下一步,进入字段映射,选择确定。
3.3、对以接口的方式对外共享的数据采集-接口采集
企业数据会以接口的方式对外共享,虎符的接口采集目前支持 Http/Https 和 WebService 协议,通过配置的方式快速完成这些数据的采集。
Http/Https
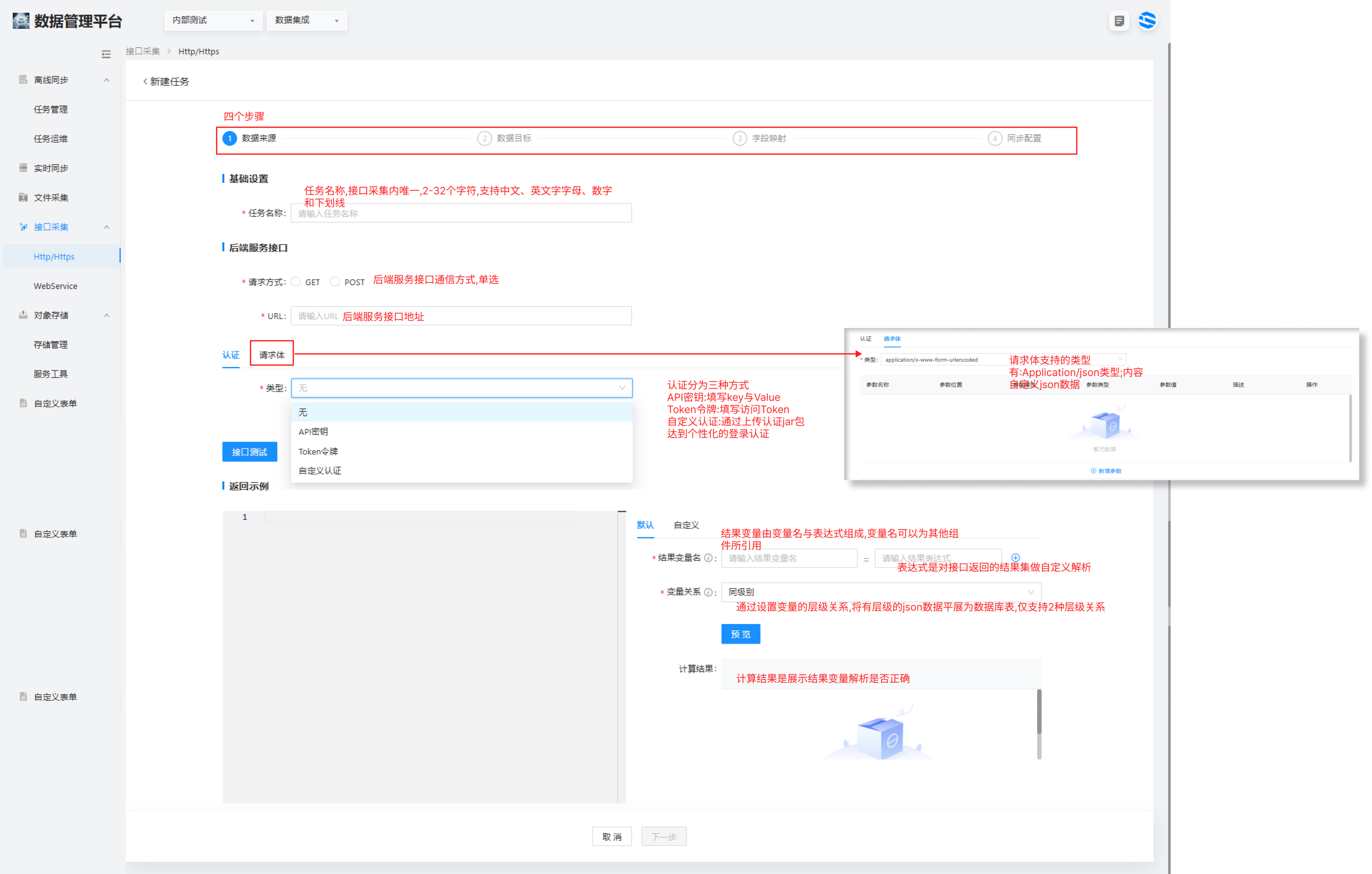
1.选择数据集成 > 接口采集 > Http/Https进入列表页面。
2.点击新建任务配置各项参数。
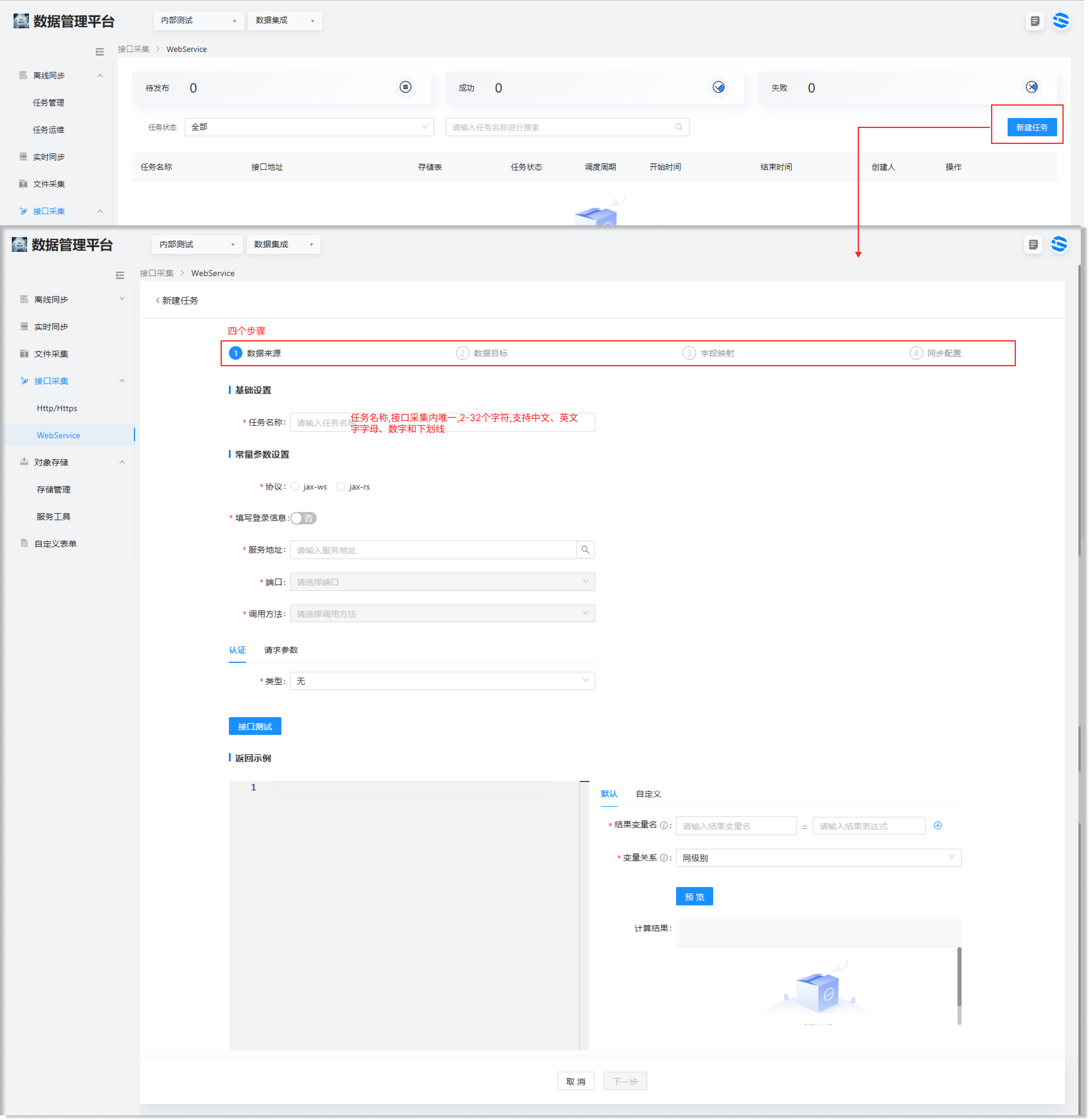
WebService
1.选择数据集成 > 接口采集 > WebService进入列表页面。
2.点击新建任务配置各项参数。
3.4、采集各种格式的 excel 文件
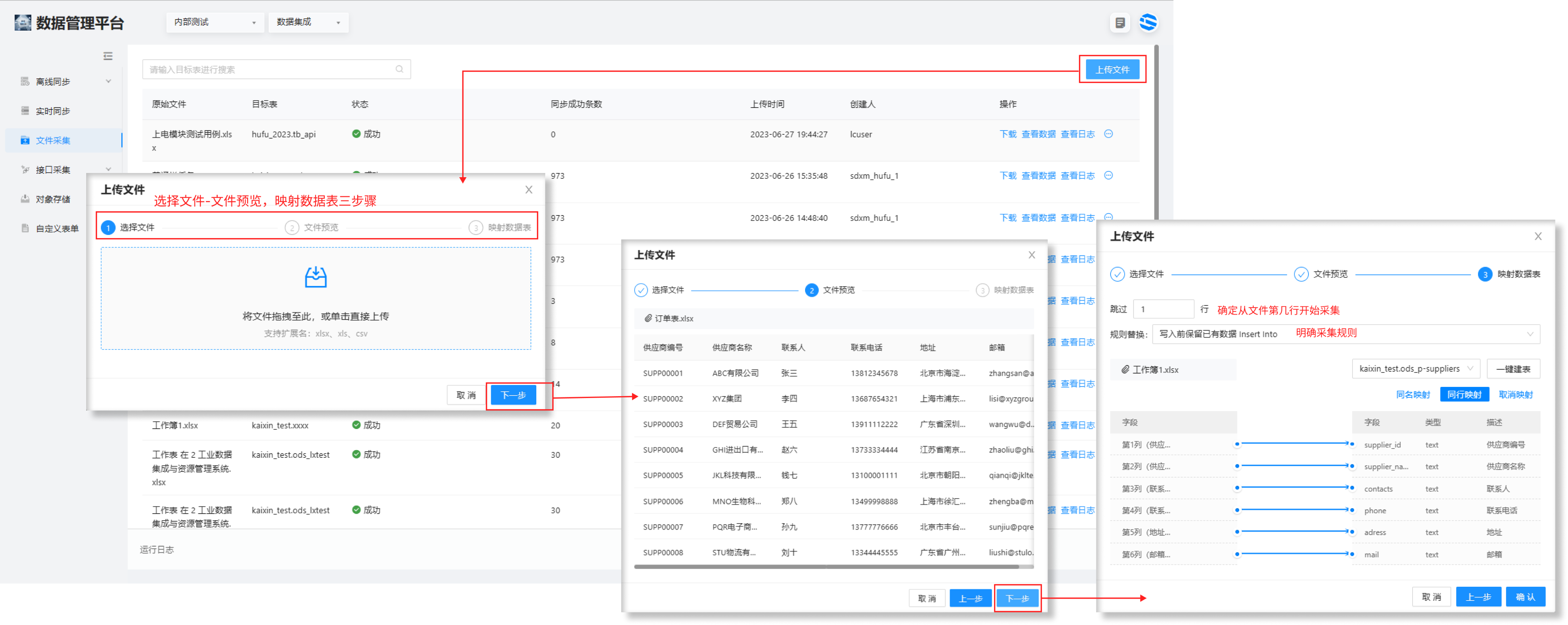
文件采集(采集各种扩展名的 excel 文件)
文件采集支持将 xlsx、xls、csv 内的数据进行采集,将文件数据以数据表的形式存储在虎符中。
操作步骤:
选择右上角上传文件 >点击中间上传区域上传文件 > 点击下一步,预览文件 >点击下一步映射数据表,配置映射的相关参数。
3.5、非结构化数据的采集-存储管理
对象存储
对象存储是面向非结构化数据的一项集采集、存储与管理的服务,提供海量、安全、低成本、高可靠的数据存储能力。存储管理用于管理对象的存储,在上传任何文件到存储服务之前,需先创建存储空间。服务工具支持客户端工具与 JavaSDK,用于外部管理或使用对象存储服务.
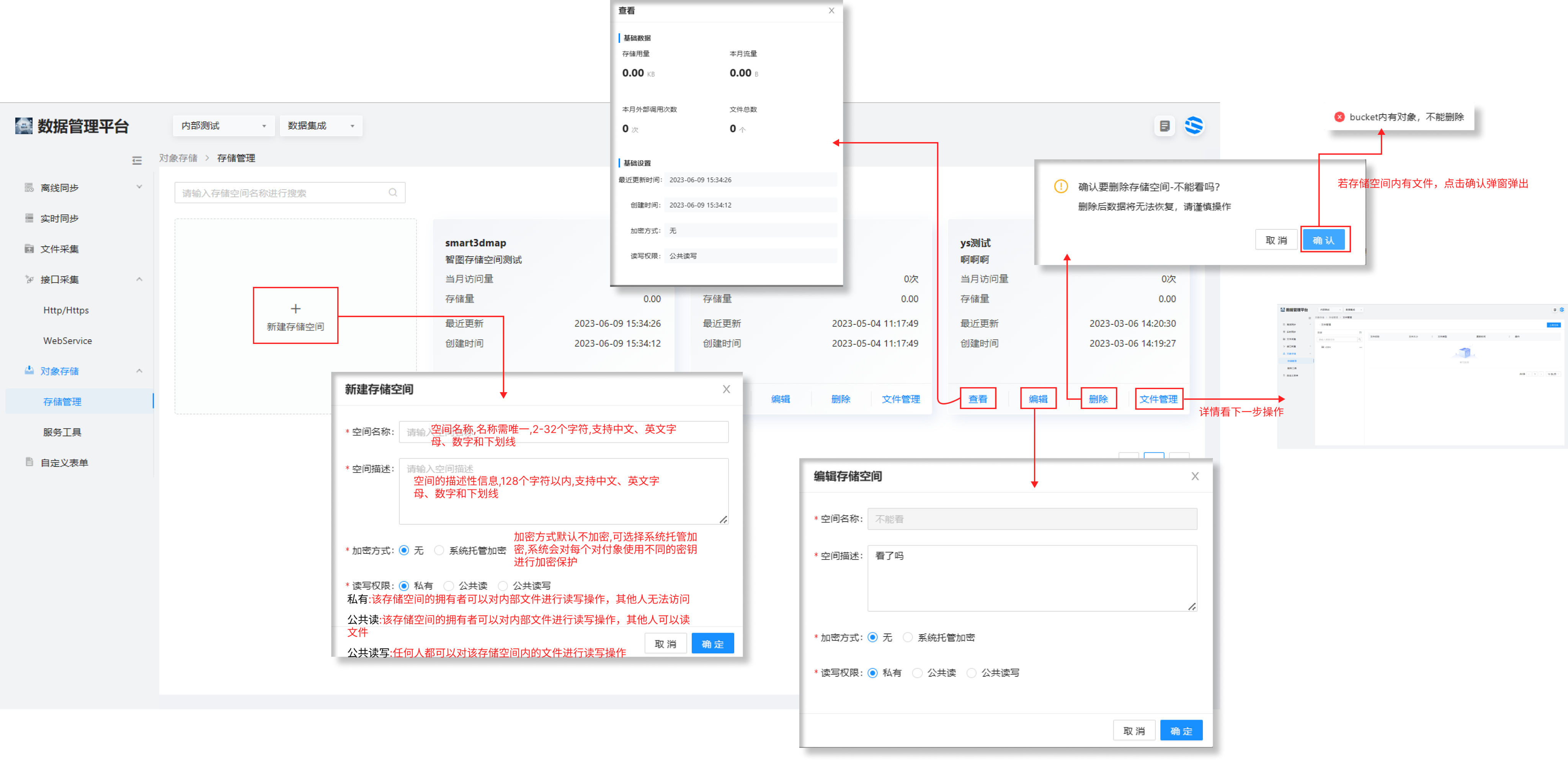
存储管理
存储管理用于管理对象的存储,在上传任何文件到存储服务之前,需先创建存储空间。
操作步骤:
1.选择数据集成 > 对象存储 > 存储管理进入列表页面。
2.单击左上角新建存储空间配置各项参数。
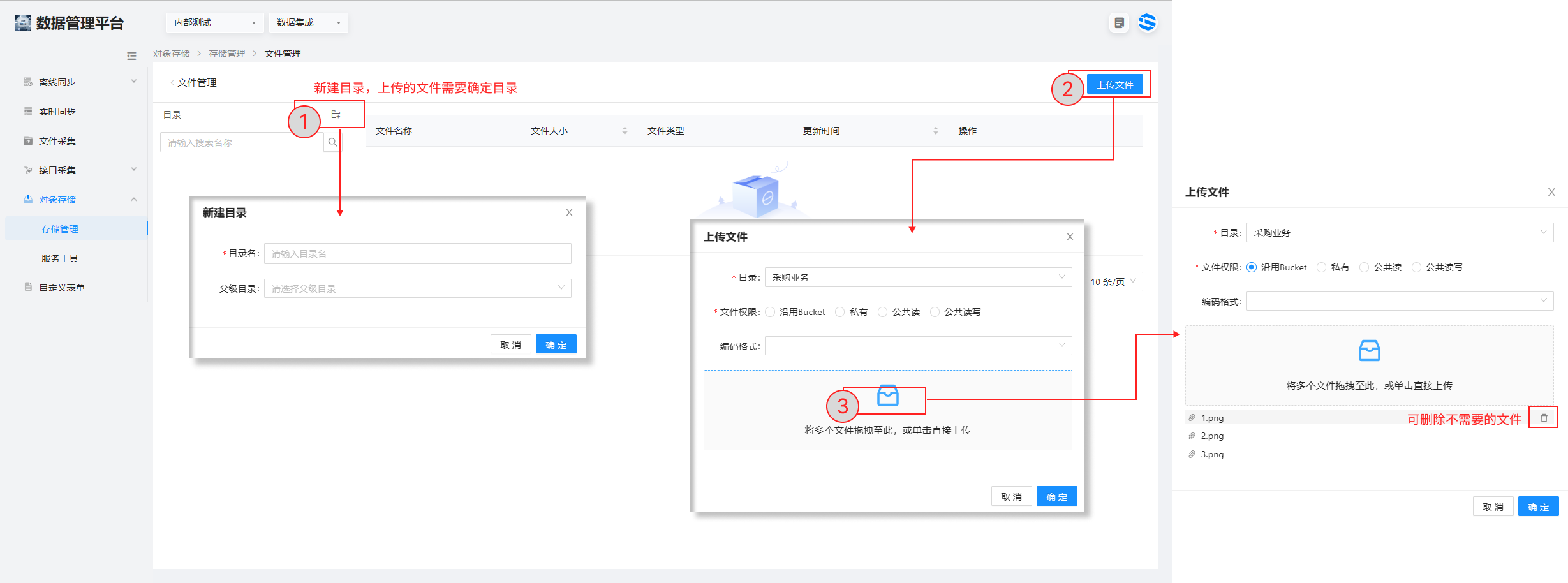
3.点击文件管理,进入列表页面 > 点击左上的新建目录,设置文件目录
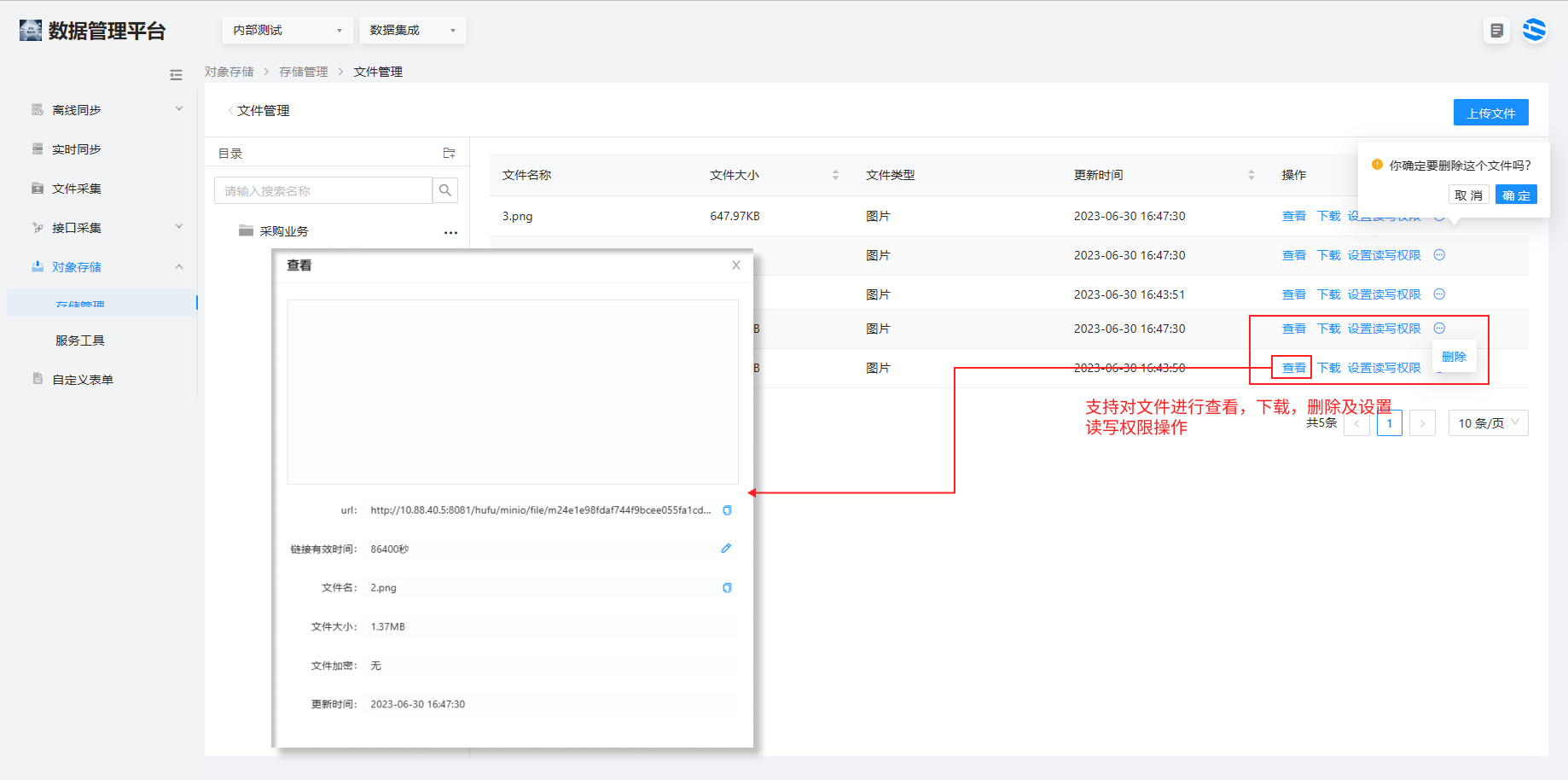
4.点击右上角上传文件进行文件的上传。
4.每个对象均支持查看明细、下载、设置读写权限、删除动作。
注:此处的设置读写权限仅针对单个对象,不影响整个存储空间的权限设置。
5、查看页面支持以连接的方式向外输出,且支持连接的有效期设置。
3.6、线下数据的采集-自定义表单
自定义表单
自定义表单用于创建一个个性化填报页面,发布到终端让用户填报数据。创建完成的表单只有发布之后才能被外部用户访问,表单的发布支持无认证方式与有认证方式两种。
操作步骤:
1、选择数据集成 > 自定义表单进入列表页面。支持表单的发布、
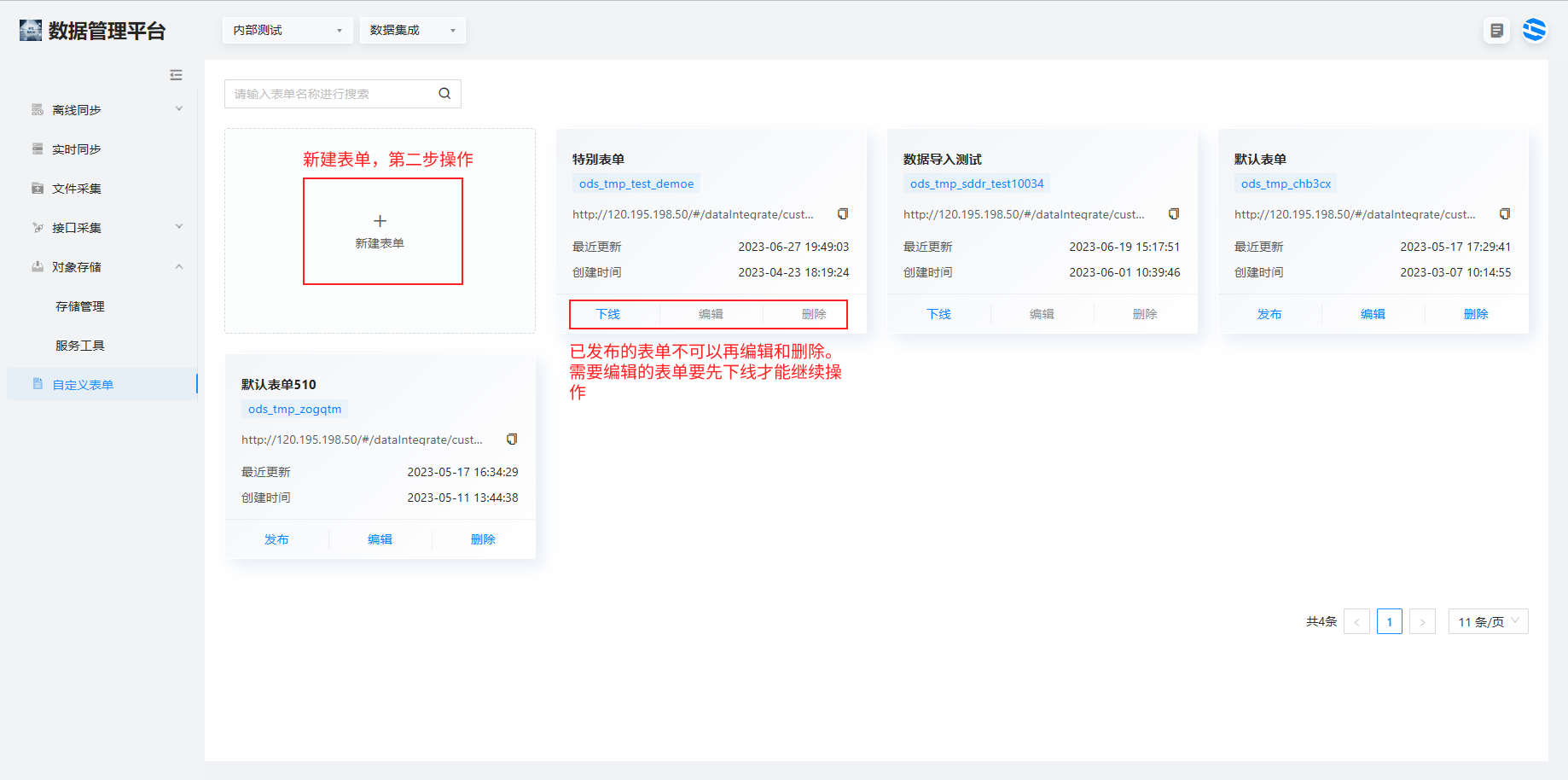
2、点击新建表单进入页面,由左侧的组件拖入画布中配置表单。

4、数据开发
数据开发是对集成的数据进行 ETL 处理,虎符数开发平台支持批数据的离线开发和流数据的实时开发,通过组件
化的开发方式和全托管的任务调度,快速构建企业数仓,同时可视化的界面可以清晰数据流向。
4.1 数据的离线开发
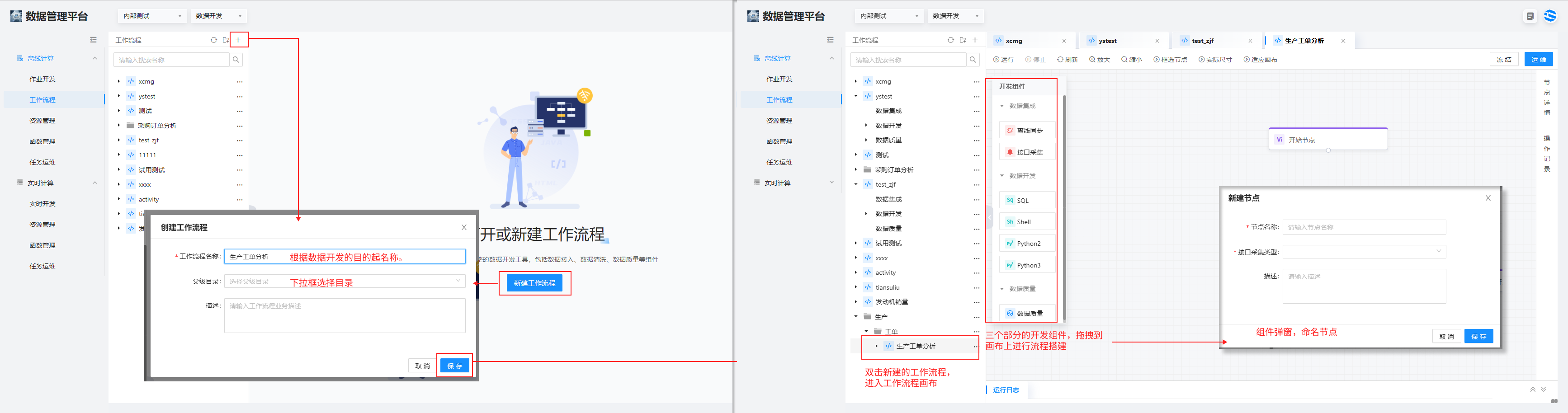
1、选择工作流程 > 点击“+”创建工作流程
工作流程名称:生产工单分析
父级目录选择生产-工单
2、双击新建的流程进入工作流程画布界面,拖拽数据开发组件搭建开发流程.
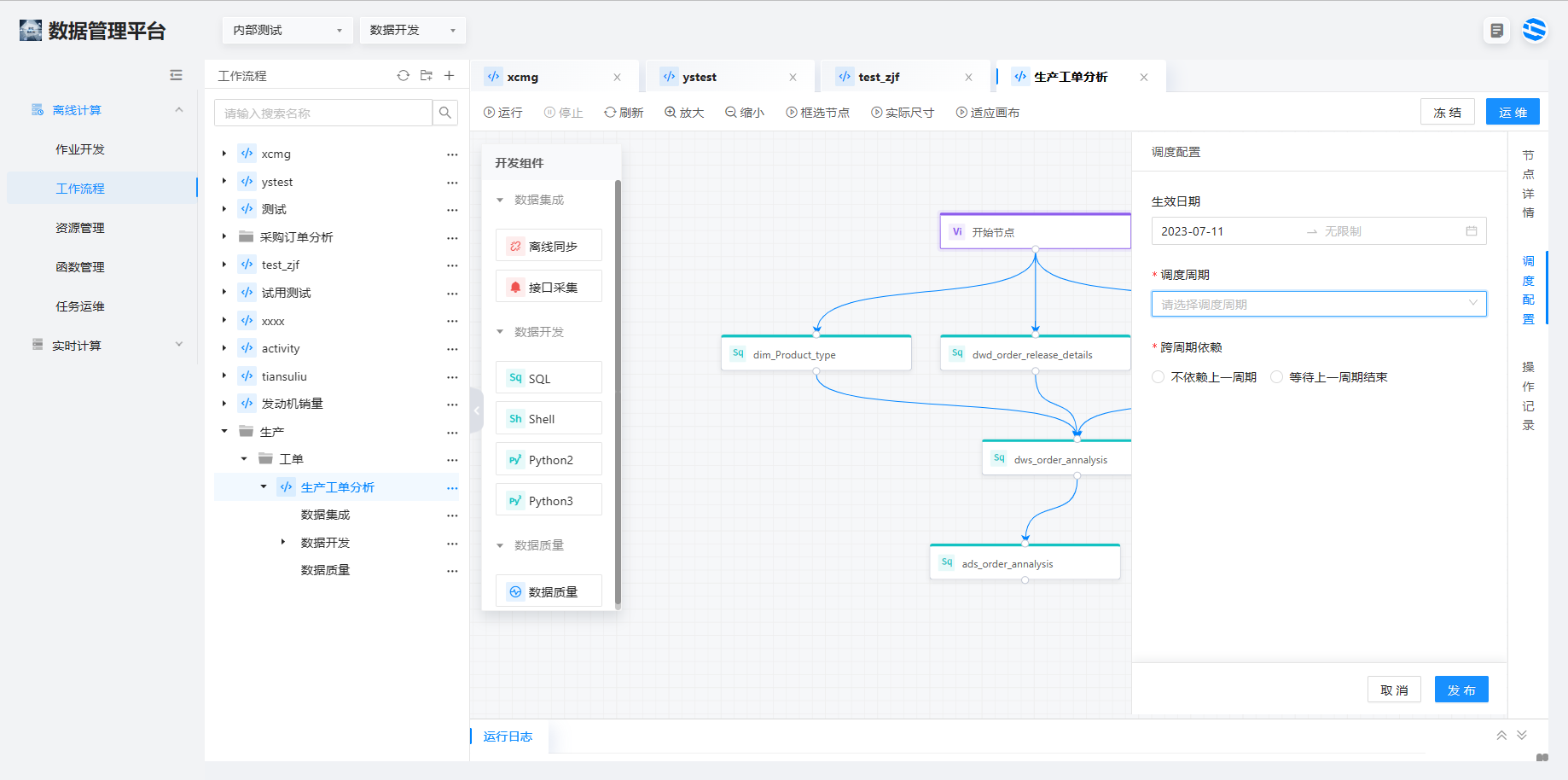
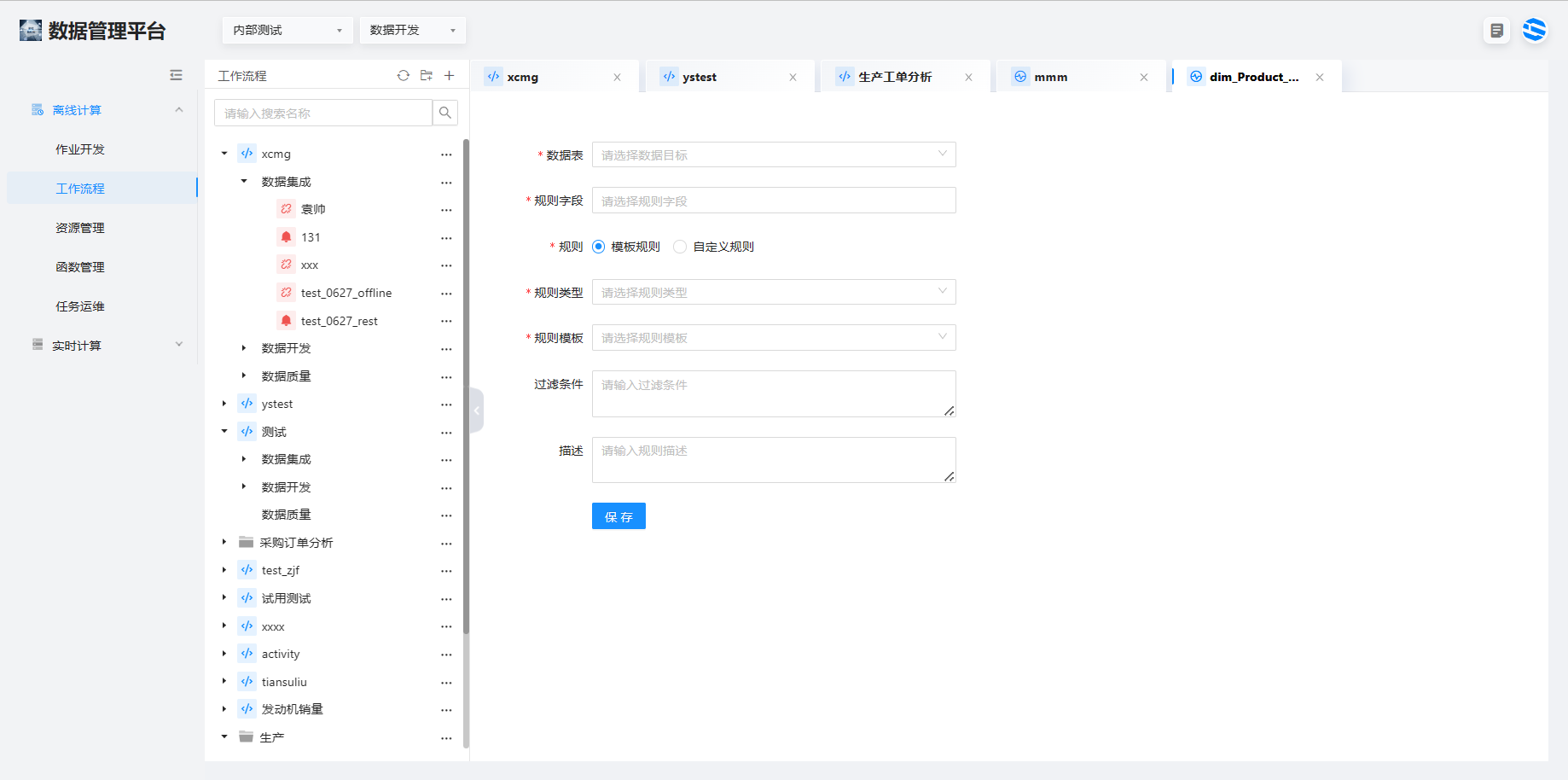
3、弹窗上节点的命名以 dim、dwd、dws 层的表来命名,这些表已经在模型设计的各个层中被建立,依次建立名称为 dim_Product_type、dwd_order_release_details、dwd_order_execution_details、dws_order_annalysis、ads_order_annalysis 几个数据开发组块,和相应的数据质量组件。
4、点击开始节点模块,点击侧面的调度配置,填写调度周期,选择不依赖上一周期。
5、双击 dim_Product_type 模块,进入脚本编写界面。
truncate table dim_Product_type;
insert into dim_Product_type
select * from ods_Product_type;
6、双击 dwd_order_release_details 模块,进入脚本编写界面,对数据进行数据清洗保证数据质量,
truncate table dwd_order_release_details;(清空目标表中的数据)
insert into dwd_order_release_details
select * from ods_order_release_details;(查询调用贴源层表的数据并完成数据的清洗)
7、双击 dws_order_annalysis 模块,进入脚本编写界面,汇总基本指标,对 dwd 表数据进行基本指标的 sum 或 count ,一般不进行多表交叉计算。当数据指标关联维度比较少,比较简单的时候,可以直接从 dwd 层连接到 ads 层。
示例:
INSERT INTO dws_order_analysis (order_key, order_date, product_type_key, execution_status_key, order_quantity, revenue)
SELECT
a.order_key,
a.order_date,
b.product_type_key,
c.execution_status_key,
a.order_quantity,
a.order_quantity * b.price AS revenue
FROM dwd_order_release_details AS a
JOIN dim_Product_type AS b ON a.product_type = b.product_type
JOIN dwd_order_execution_details AS c ON a.order_key = c.order_key;
8、双击 ads_order_annalysis 模块,进入脚本编写界面。
ads 表作为分析应用层,按具体分析需求,进行交叉分析。
9、可拖拽数据质量组件检验数据质量是否符合业务需要,可连接在开始点模块上,也可以连接在各个层级的表上。
4.2 实时开发
4.2.1 FlinkSQL 类型任务的开发
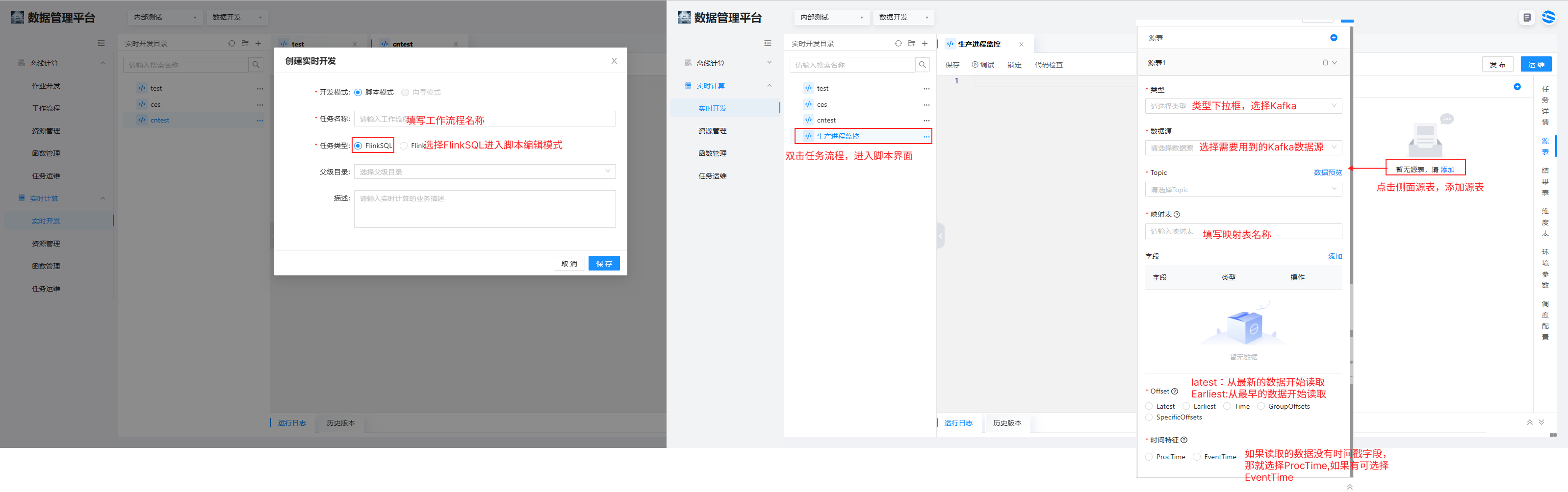
选择实时计算 > 实时开发 > 创建新的实时任务“生产进程监控”,任务类型选择 FlinkSQL 模式;
点击左侧的任务目录栏的“生产进程监控”进入脚本编辑界面
源表点击右侧边栏的源表,添加源表,选择下拉框内 MES 系统中的 Kafka 数据源,填写映射表名称为 production_monitoring;
字段选择添加 yield;Device status 等
offest 选择 latest;
时间特征选择 ProcTime
4.2.2 Flink 类型任务的开发
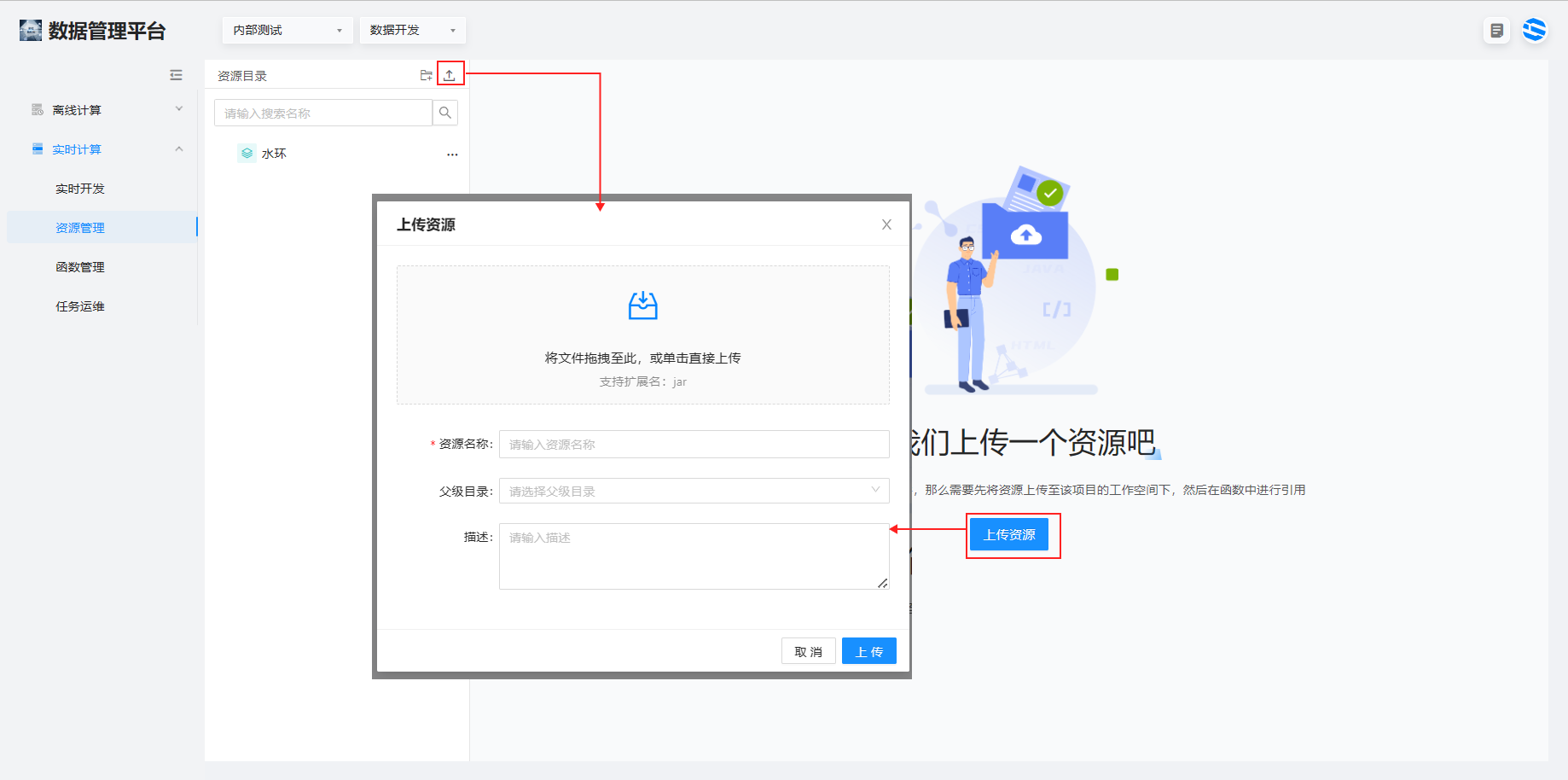
1、选择实时计算>资源管理> 点击资源目录栏右上角或者界面中间上传资源,出现上传资源弹窗
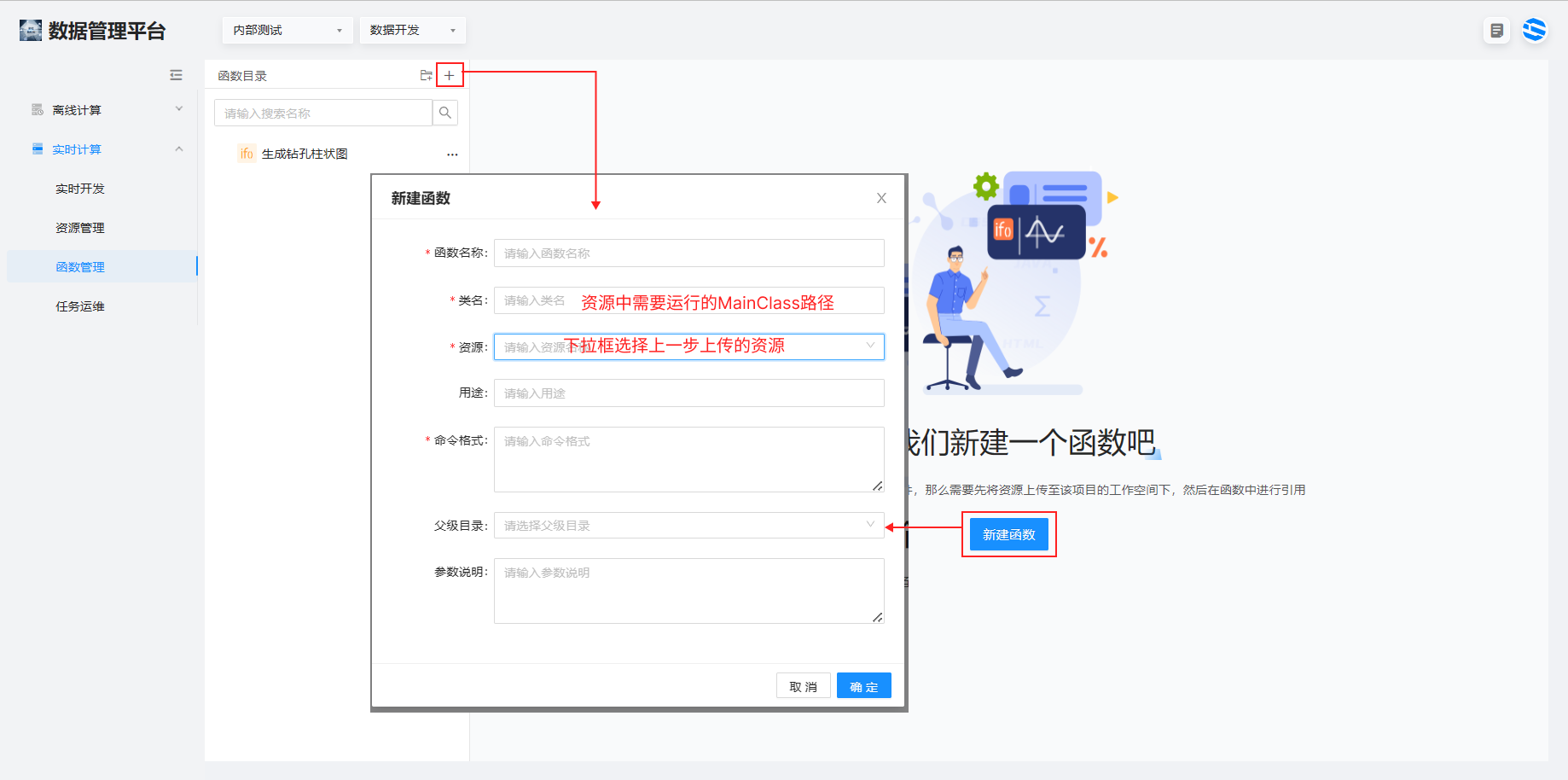
2、选择实时计算> 函数管理> 点击函数目录栏右上角或者界面中间新建函数,出现新建函数弹窗
3、选择实时计算 > 实时开发 > 新建实时任务

5、数据信息查看与溯源-数据资产
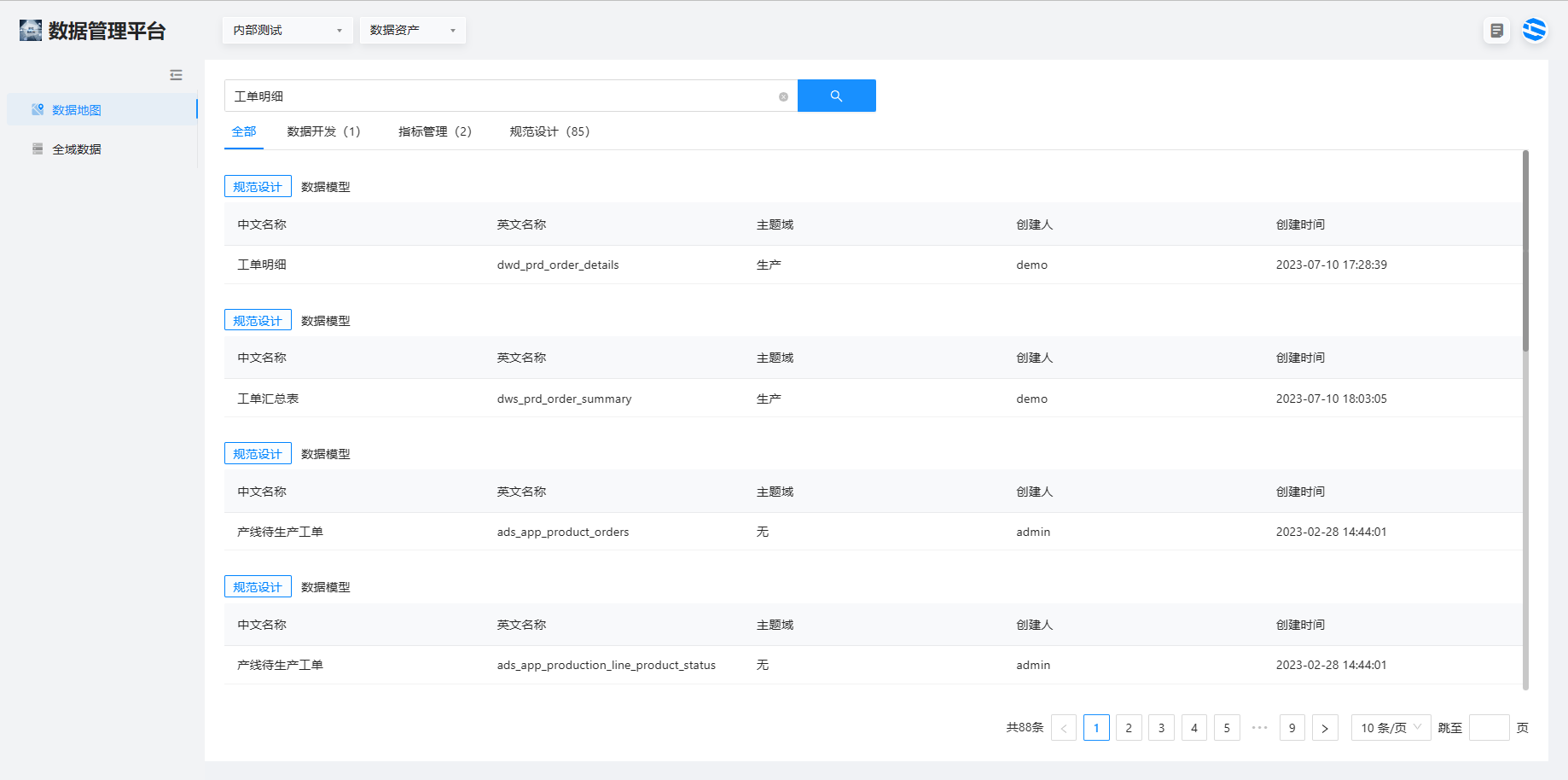
上述的数据集成与开发,沉淀数据,形成数据资产。用户可进入数据地图进行所需数据的搜索。
1、虎符首页 > 选择数据资产,进入数据地图,可按照关键词进行搜索,获得相关的数据信息
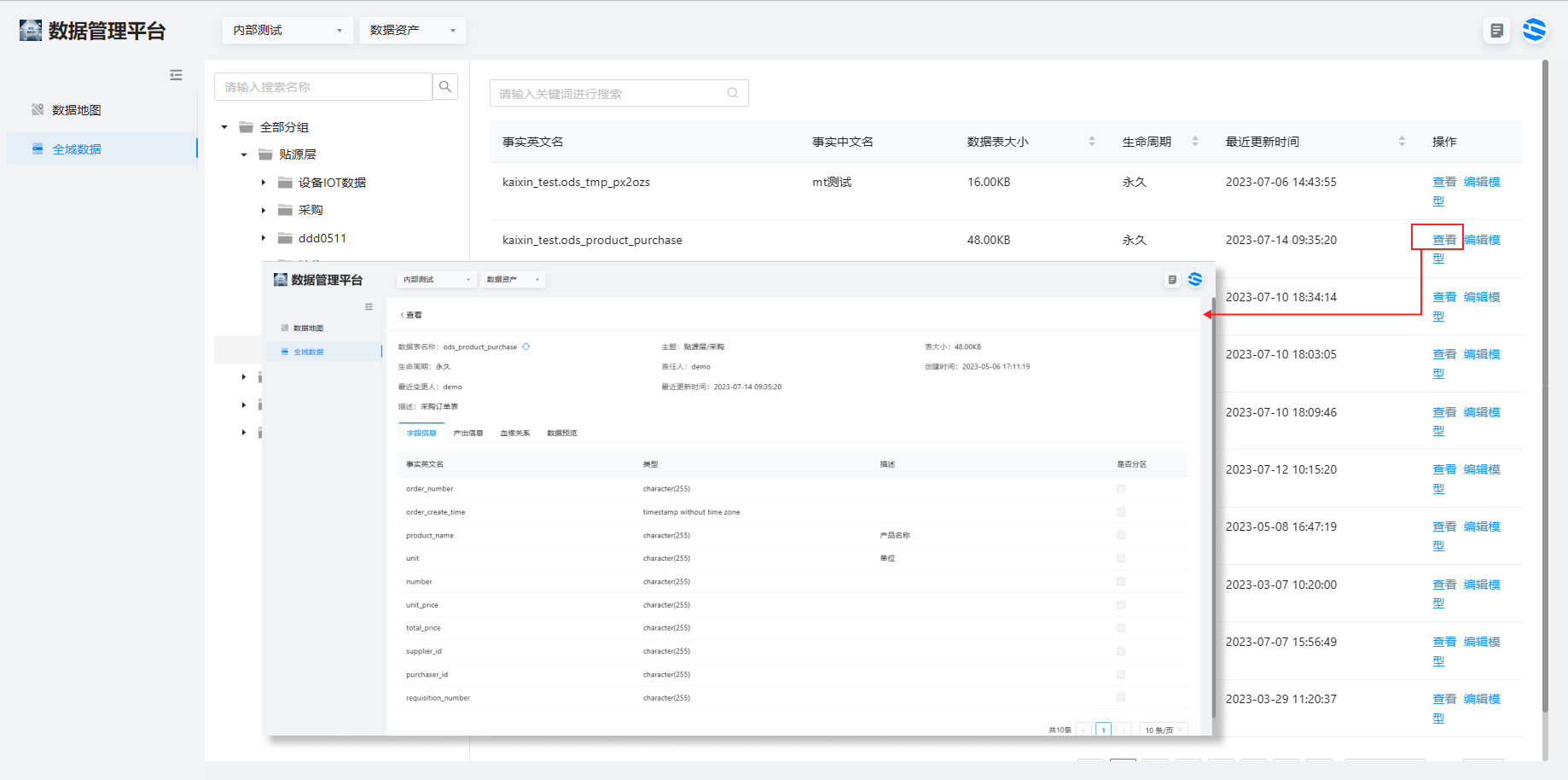
2、选择全域数据,可在目录栏选择不同层级的数据查看该层的数据列表,点击查看,查看数据表的字段、血缘和数据信息
6、分享处理过的生产相关数据表——数据服务
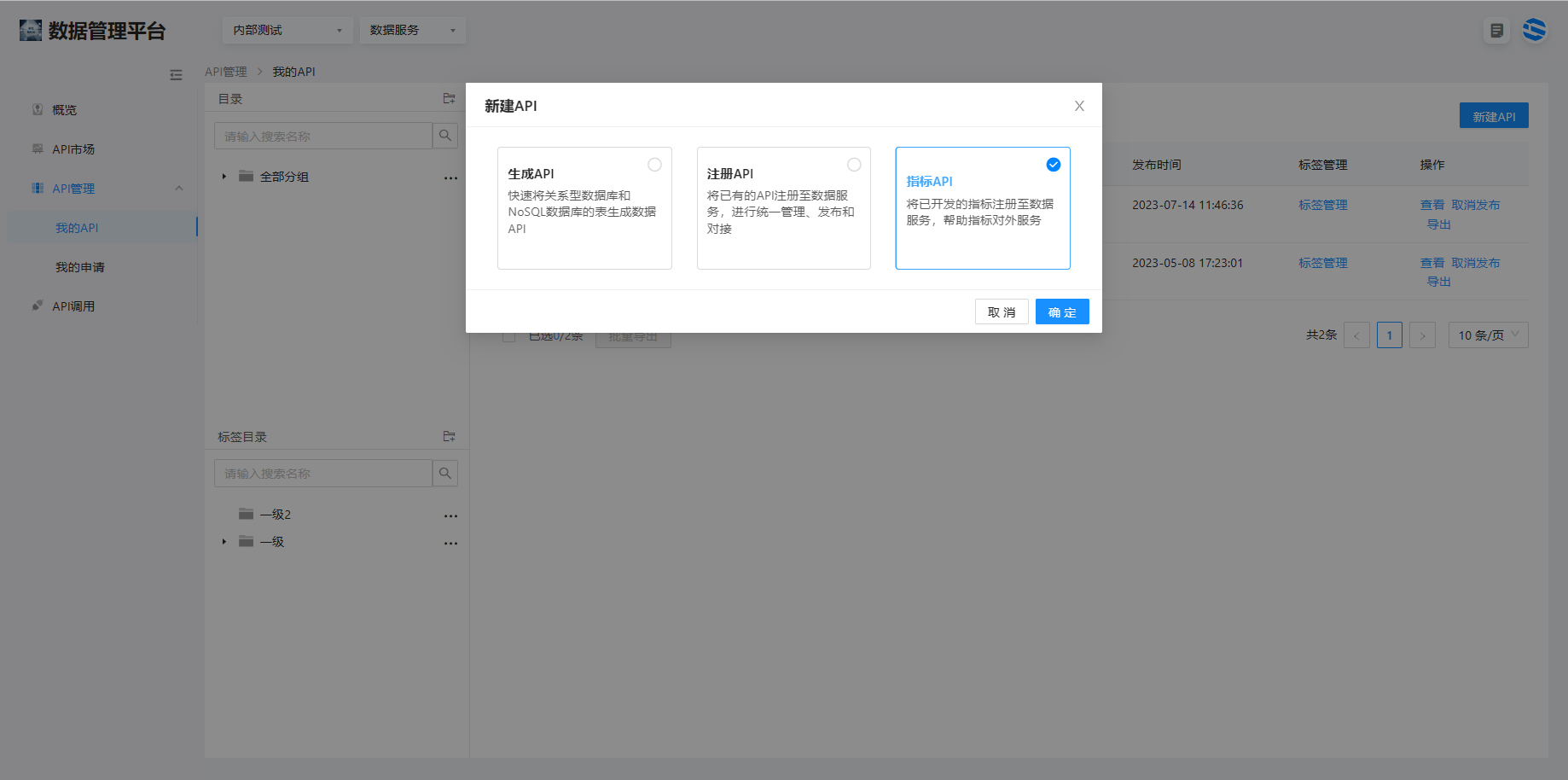
数据服务提供快速将数据表生成数据 API 的能力
1、生成 API
选择数据服务 >API 管理 > 我的 api> 点击右上角新建 API
API 名称:工单明细表
APIPath:/gdmxb
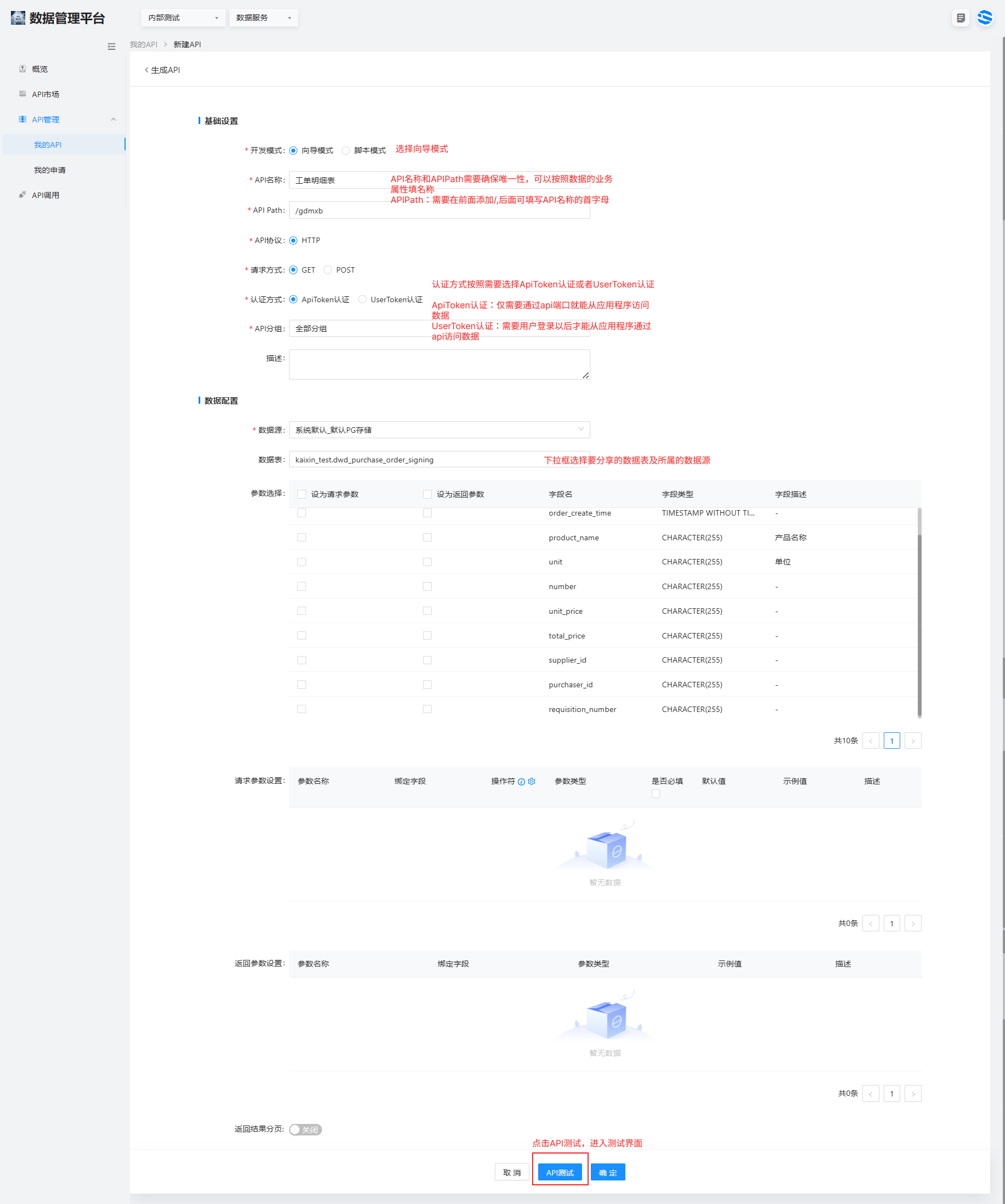
2、API 发布、申请和授权使用
二、基于指标的数据集成开发
“某车间生产合格率”指标开发
1、指标的开发、管理
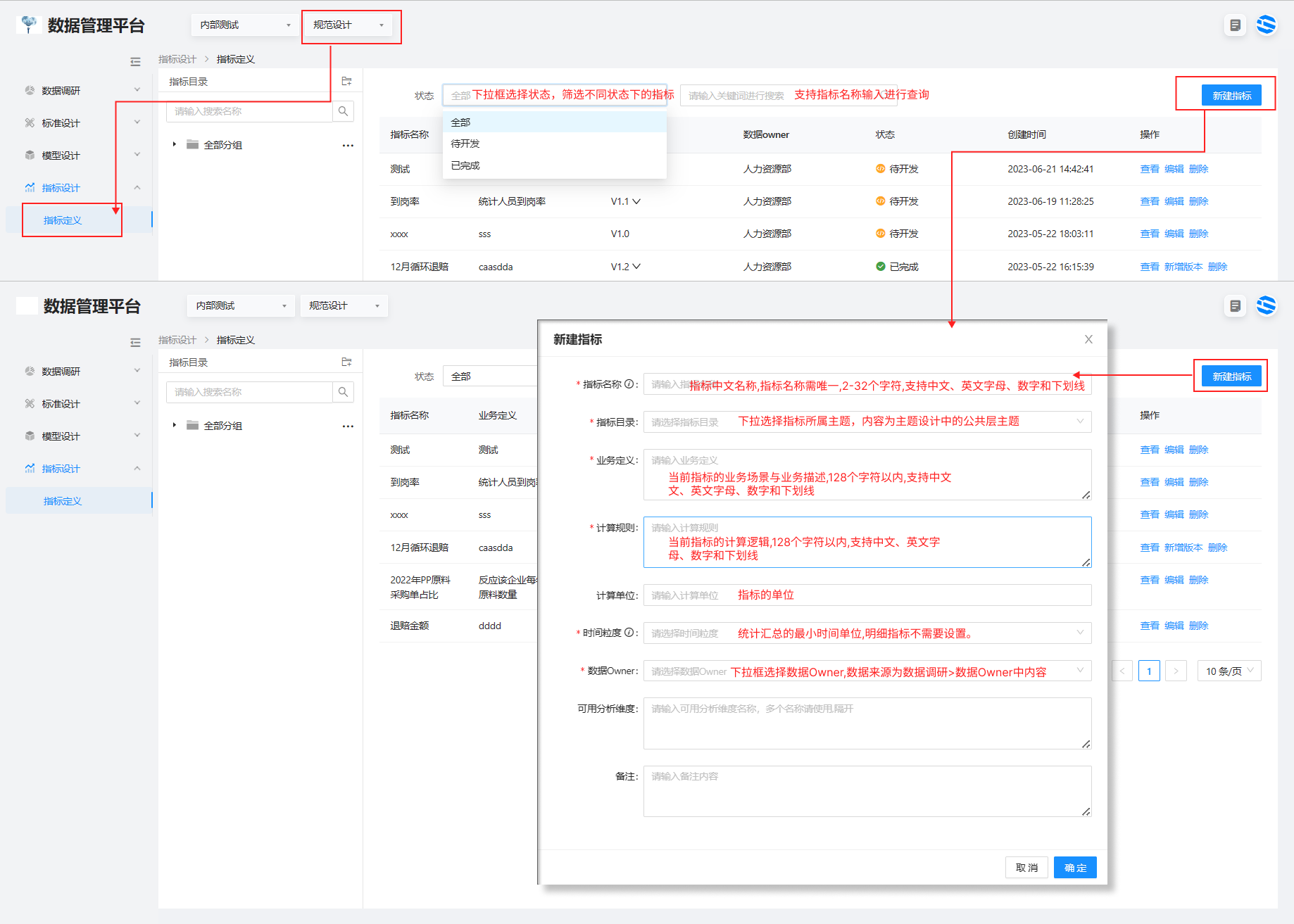
1、指标定义、编辑
操作步骤:1.选择规范设计 > 指标设计 > 指标定义 进入列表页面 > 选择右上角新建指标,进入指标定义页面
指标名称:车间生产合格率
指标目录:生产-生产质量监控
业务定义:对车间生产质量的考核
计算规则:车间生产合格率=合格产品数 ➗ 总生产产品数
时间粒度:日
数据 owner:生产部
2、指标相关数据的注册
该指标涉及到了生产监控,计划排产,车间管理等数据表,这些数据在企业的 MES 系统中,将企业的 MES 业务系统注册至虎符
选择规范设计>数据调研>数据管理> 右上角点击新增数据源,将业务系统注册到虎符上。
3、指标的数据模型构建
3.1、选择规范设计>数据调研>主题设计> 右上角点击新建主题
贴源层:生产监控数据;公共层:生产—生产监控;应用层:车间生产合格情况
3.2、选择规范设计>数据调研>数据 owner> 右上角点击新建 owner
owner 名称:生产部
3.3、选择规范设计>标准设计>标准定义> 右上角点击新建标准
依次新建车间名称,生产产量,合格数量等字段标准
3.4、选择模型设计> 总线矩阵 > 右上角点击新建事实行、维度列
3.5、选择模型设计> 贴源模型 > 右上角点击新建贴源模型
将 MES 系统中的相关数据表,例如生产监控表,车间排产表等构建到贴源层
3.6、选择模型设计> 公共模型 > 右上角点击新建公共模型
3.7、选择模型设计> 总线矩阵 > 点击事实行、维度列,关联公共模型表
4、指标相关数据的集成
将生产监控表、车间明细表等相关数据注册到虎符平台上
4.1 选择数据集成 > 离线同步 > 任务管理 > 右上角点击新建离线任务,将生产监控表等集成至虎符的默认 PG 存储
目标表选择在模型设计中贴源层模型
5、指标开发
选择数据开发 > 离线计算
选择从左上角下拉栏选择指标管理,进入指标管理界面,点击指标行的操作列指标开发 >(新建工作流程)>
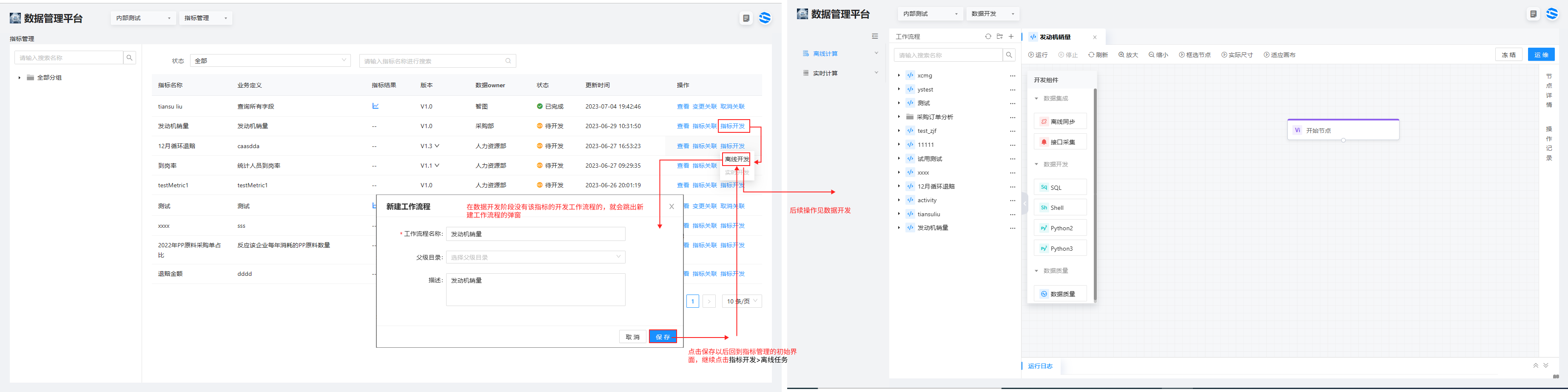
6、指标分享
选择数据服务 > 我的 API> 点击右上角新建 API> 选择指标 API,点击确定进入指标 API 编辑界面。