算盘安装手册
算盘是基于docker+kubernetes服务,采用流计算,noflo等架构开发出的一个工业App开发平台
1.环境准备
1.1.硬件环境
请参考下表,准备算盘硬件环境:
1.1.1.各版本算盘环境需求
A:典型配置要求:
| 节点名称 | 节点类型 | 节点个数 | CPU | 内存 | 硬盘 |
|---|---|---|---|---|---|
| 算盘单节点版 | 单master节点 | 1 | 16 Core | 64G | 2TB |
| 算盘集群版 | 主节点 | 1 | 8 Core | 32G | 1TB |
| 从节点 | 2 | 8 Core | 32G | 1TB |
B:算法训练配置要求:
| 节点名称 | 节点类型 | 节点个数 | GPU | CPU | 内存 | 硬盘 |
|---|---|---|---|---|---|---|
| 算盘单节点版 | 单master节点 | 1 | nvidia(1块及以上) | 16 Core | 64G | 2TB |
| 算盘集群版 | 主节点 | 1 | nvidia(0块或者1+块) | 8 Core | 32G | 1TB |
| 从节点 | 2 | nvidia(0块或者1+块) | 8 Core | 32G | 1TB |
C:建议配置要求:
C1:(可访问外网):
| 节点名称 | 节点类型 | 节点个数 | CPU | 内存 | 硬盘 |
|---|---|---|---|---|---|
| 算盘集群版 | 主节点 | 1 | 16 Core | 64G | 2TB(建议做RAID) |
| 从节点 | 2 | 16 Core | 64G | 2TB(建议做RAID) |
C2:(不可访问外网):
| 节点名称 | 节点个数 | CPU | 内存 | 硬盘 |
|---|---|---|---|---|
| 算盘单节点版 | 1 | 16+ Core | 64+G | 4TB(建议做RAID) |
说明:
支持定制版本环境
1.1.2.其他要求:
- 系统:CentOS7.6 64位,允许 root 访问
- 网络:推荐使用万兆网络,并保证集群机器处于同一网段,配置 IP,NTP
- 分区:通常情况下(磁盘没有做RAID),建议除数据磁盘外,系统盘统一分配至/根分区;无需额外挂载/var等分区。(如一共2TB的空间,可以按照500GB挂载至/分区,1.5TB挂载至/data分区的方式来划分)。
- 操作系统:服务器语言建议使用英语/English
1.1.3.附加说明:
- 算盘支持单节点部署 或者 集群方式部署。在私有云环境中建议使用集群版;在边缘设备环境中建议使用单节点版本。
- 在满足硬件性能要求的前提下,以上节点可以通过物理机或者虚拟机(推荐基于kvm或vmware的虚拟机)的形式进行部署;专有云环境推荐使用ECS进行部署。
- 在典型集群版配置下,可以并发运行8-10个算盘项目(平均每个项目5-10节点)。
- 算盘支持离线运行和在线运行。如私有云环境内网无法使用外网,可单独说明。
- 在典型集群版配置下,默认用于服务部署的节点有3个。支持弹性扩容,以满足计算和存储需求。
1.1.4.基础配置
假设算盘集群配置为典型配置,即有3个节点,每个节点配置为8核32G硬盘1TB
各节点IP如下:
192.168.1.101
192.168.1.102
192.168.1.103
其中:
192.168.1.101作为算盘集群master节点
192.168.1.102,192.168.1.103作为算盘node节点
1.1.4.1.配置hosts映射
在所有节点的/etc/hosts中添加:
192.168.1.101 192.168.1.101
192.168.1.102 192.168.1.102
192.168.1.103 192.168.1.103
1.1.2.2.配置hostname
在所有节点上,分别修改hostname为各自的ip地址,192.168.1.101--192.168.1.103
hostnamectl set-hostname {your_hostname}
1.1.2.3.配置ssh免登录
在192.168.1.101节点上执行:
ssh-keygen -t rsa -b 2048
并分别拷贝至所有节点:
ssh-copy-id 192.168.1.101
ssh-copy-id 192.168.1.102
ssh-copy-id 192.168.1.103
1.2. 软件系统环境
1.2.1. 防火墙
安装算盘集群需要关闭服务器防火墙。如客户政策安全等原因无法满足要求需提前说明。
1.2.2. swap分区
安装算盘集群需要关闭swap分区。如客户政策安全等原因无法满足要求需提前说明。
1.2.3. SELinux
安装算盘集群需要关闭SELinux(针对CentOS操作系统)。如客户政策安全等原因无法满足要求需提前说明。
1.2.4. ipV6
安装算盘集群需要关闭ipV6相关功能。如客户政策安全等原因无法满足要求需提前说明。
1.2.5. 端口
安装算盘集群需要使用80, 443, 6443, 30000, 30002, 9877, 10250-10258等端口,如有冲突请提前说明。
1.3.安装Nvidia GPU 驱动
注:只针对含有GPU的机器,建议事先安装好Nvidia驱动
这边也提供了CentOS和Ubuntu的nvidia GPU驱动安装文档:
- CentOS7:https://xuelangyun.yuque.com/suanpan_doc/public/gpu-centos7
- Ubuntu1804:https://xuelangyun.yuque.com/suanpan_doc/public/gpu-ubuntu
更多详细资料可以参考Nvidia官方文档:https://www.nvidia.com/en-us/drivers/unix/
1.4.下载算盘安装包
算盘安装包的下载链接请联系算盘项目组获取。解压之后目录如下:
2.Docker安装
注:2.1/2.2选一执行或者不执行,第3步步骤会自动执行2.2步骤
2.1.在线安装
根据机器所安装的操作系统以及版本来选择安装对应的版本(以CentOS为例):
https://docs.docker.com/engine/install/centos/
2.2.离线安装
注:
1)除了在线安装,算盘这边也提供了docker离线安装的方案。
2)在第3步,安装Kubernetes的时候也会包含docker的安装检查以及安装。
3)离线安装不一定会安装最新版本的docker。本例中以docker-ce:19.03.2版本为例。
2.2.1.离线安装步骤

cd docker/
chmod a+x deploy.sh
./deploy.sh
2.2.2.安装检查
执行如下命令,查看结果
docker version
如下图,结果中能够看到client和server两块内容则表示docker 安装成功。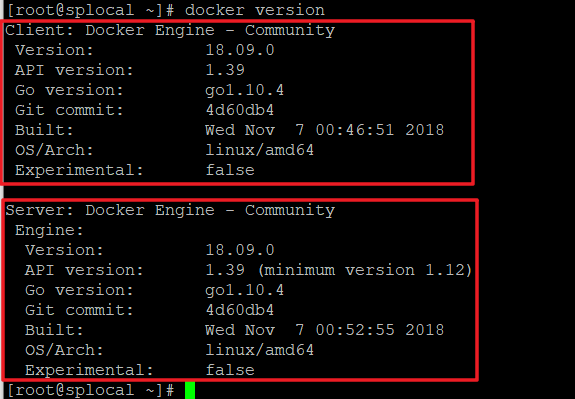
3.Kubernetes安装
在解压安装包的根目录,执行如下命令
./deploy-cluster.sh -m 192.168.1.101 -w 192.168.1.102,192.168.1.103

3.算盘安装
在解压安装包的根目录,执行如下命令
./deploy-suanpan-full.sh --minio 192.168.1.101 --redis 192.168.1.101 --postgres 192.168.1.101 --kubeconfig=/etc/kubernetes/admin.conf --masterfile={masterfile} --workerfile={workerfile}

4.算盘运行检查
本节内容用于使用者对算盘应用的自我检查
4.1.算盘环境开机检查
注:算盘环境依赖于Linux systemd 服务,所有的对应服务:docker/Kubernetes 等会随系统自启,无须用户介入启动。
4.1.1.K8S检查:
4.1.1.1.节点检查
1, SSH 进入192.168.1.101环境
2, 终端执行命令:
kubectl get nodes 注:将会看到所有使用中的节点,请检查STATUS状态是否为“READY”。如命令本身执行出错,或者状态不为“READY”,请联系无锡雪浪云。
注:将会看到所有使用中的节点,请检查STATUS状态是否为“READY”。如命令本身执行出错,或者状态不为“READY”,请联系无锡雪浪云。
4.1.1.2.系统服务检查
1, SSH 进入192.168.1.101环境
2, 终端执行命令:
kubectl get pods -n kube-system 注:将会看到所有算盘环境的系统pod,请检查STATUS状态是否为“Running”。如命令本身执行出错,或者状态不为“Running”,请联系无锡雪浪云。
注:将会看到所有算盘环境的系统pod,请检查STATUS状态是否为“Running”。如命令本身执行出错,或者状态不为“Running”,请联系无锡雪浪云。
4.1.1.3.运行项目检查
1, SSH 进入192.168.1.101环境
2, 终端执行命令:
kubectl get pods -n user-100934 注:
注:
1, name字段的第二个部分(如上图7628,7633)对应算盘中运行的项目。
如果没有目标项目正在运行可以进入雪浪算盘,进行部署操作。 2, 可以检查“STATUS”字段,查看是否为“Running”。
2, 可以检查“STATUS”字段,查看是否为“Running”。
如果没有Running,说明运行出错。可以在页面上检查节点运行出错的日志。 点击“新窗口打开”/“预览”可以查看日志信息。
点击“新窗口打开”/“预览”可以查看日志信息。
根据日志信息自行解决或者联系雪浪云同事。
4.1.2.算盘使用简介
4.1.2.1.概览页
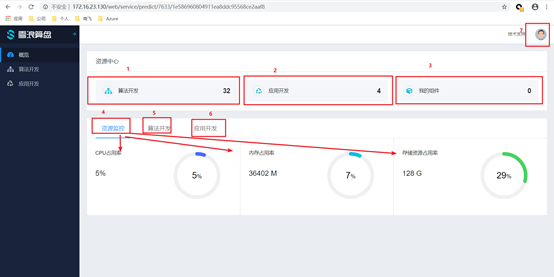 1, 查看目前有多少个算法开发项目
1, 查看目前有多少个算法开发项目 2, 查看目前有多少个应用开发项目
2, 查看目前有多少个应用开发项目
3, 查看目前有多少个我的组件
4, 查看目前部署机器的资源使用情况(存储为监控/分区)
5, 查看目前运行中的算法开发项目,以及资源使用情况。
6, 查看目前运行中的应用开发项目,以及资源使用情况。 7, 查看个人相关信息
7, 查看个人相关信息
4.1.2.2.算法开发
查看算法开发模板
4.1.2.3应用开发
查看应用开发模板