算盘运维异常问题分析
【FAQ】算盘运维异常问题分析
FAQ-1)所有服务启动正常,但是内网其他机器无法访问
 可能原因1:内网开启了防火墙
可能原因1:内网开启了防火墙
解决办法1:申请开启指定端口白名单
可能原因2:Docker0默认地址172.17.0.1与内网地址冲突
解决办法2:增加docker配置 ↓↓↓
# 编辑文件
/etc/docker/daemon.json
# 添加配置
{"bip":"177.17.0.1/24"}
# 重启docker
systemctl daemon-reload && systemctl restart docker
# 查看docker0地址
[root@k8s-master ~]# ifconfig docker0
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 177.17.0.1 netmask 255.255.255.0 broadcast 177.17.0.255
ether 02:42:51:3a:b3:35 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
FAQ-2)docker0 ip无法更新
前言:通过增加配置{"bip":"177.17.0.1"}修改docker0地址,但重启docker后docker0地址未更新
可能原因:docker进程没有完全停掉
解决办法:
# 1.尝试先停止docker服务,过会再启动docker
systemctl stop docker.socket && systemctl stop docker
systemctl daemon-reload && systemctl start docker
# 2. 上述不行,尝试重启network
systemctl restart network
# 3. 上述均不行,重启机器(100%有效)
reboot
FAQ-3)kubectl命令执行失败
可能原因1:apiserver服务异常,导致无法访问 解决办法1:检查主节点是否正常,检查apiserver容器是否存在,检查apiserver镜像是否存在
解决办法1:检查主节点是否正常,检查apiserver容器是否存在,检查apiserver镜像是否存在
[root@192 ~]# ping 192.168.73.137
PING 192.168.73.137 (192.168.73.137) 56(84) bytes of data.
64 bytes from 192.168.73.137: icmp_seq=1 ttl=64 time=1.80 ms
64 bytes from 192.168.73.137: icmp_seq=2 ttl=64 time=2.36 ms
64 bytes from 192.168.73.137: icmp_seq=3 ttl=64 time=1.86 ms
64 bytes from 192.168.73.137: icmp_seq=4 ttl=64 time=1.82 ms
64 bytes from 192.168.73.137: icmp_seq=5 ttl=64 time=3.93 ms
[root@k8s-master wenruo]# docker ps |grep k8s_kube-apiserver
094861a442ad f1ff9b7e3d6e "kube-apiserver --au…" 2 minutes ago Up 2 minutes k8s_kube-apiserver_kube-apiserver-192.168.73.137_kube-system_e7b3201fedfd2d8afb36fbaa0661fb6d_11
[root@k8s-master wenruo]# docker images |grep apiserver
k8s.gcr.io/kube-apiserver v1.13.0 f1ff9b7e3d6e 2 years ago 181MB
可能现象2:当前用户缺少kubeconfig文件 解决办法2:kubectl命令需要使用kubeconfig来运行,需要添加kubeconfig到当前用户下。
解决办法2:kubectl命令需要使用kubeconfig来运行,需要添加kubeconfig到当前用户下。
[root@k8s-master ~]# ls ~/.kube/config
ls: cannot access /root/.kube/config: No such file or directory
[root@k8s-master ~]# mkdir -p $HOME/.kube
[root@k8s-master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.73.131 Ready master 46d v1.13.0
可能原因3:k8s证书已过期 解决办法3:查看证书有效期,参考Kubernetes 证书升级进行证书升级。
解决办法3:查看证书有效期,参考Kubernetes 证书升级进行证书升级。
[root@k8s-master wenruo]# openssl x509 -in /etc/kubernetes/pki/apiserver.crt -text -noout | grep Not
Not Before: Apr 23 07:17:46 2021 GMT
Not After : Apr 23 07:17:46 2022 GMT
FAQ-4)服务无法访问,节点显示NotReady
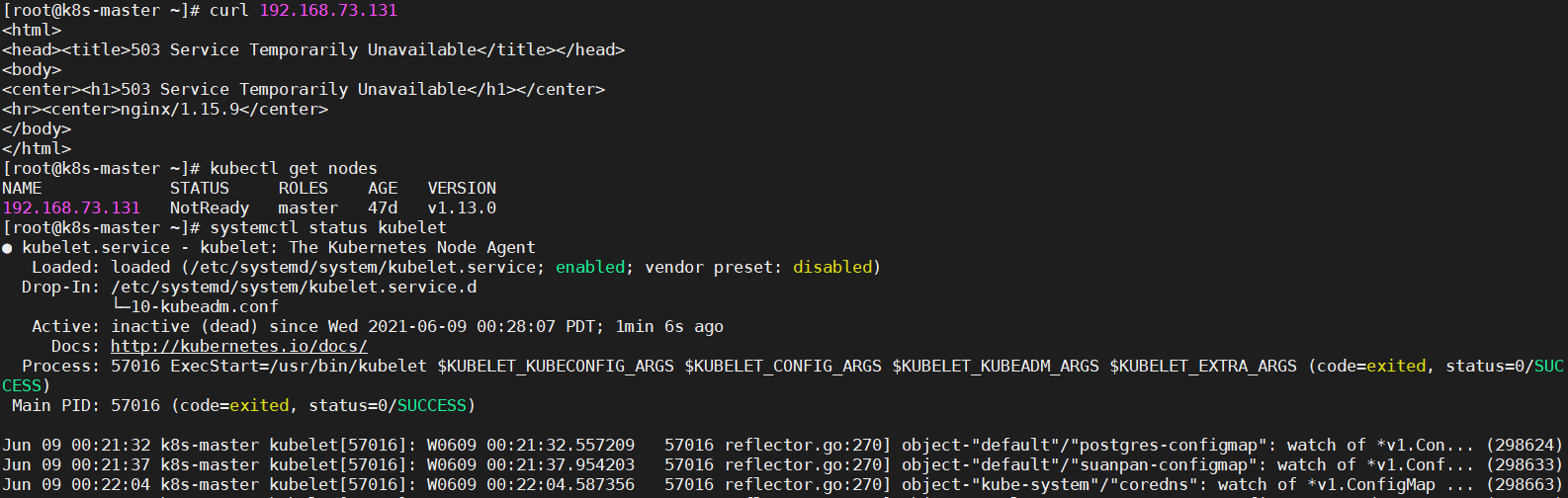 可能原因1:节点NotReady,kubelet启动异常
可能原因1:节点NotReady,kubelet启动异常
解决办法1:查看kubelet异常原因,解决后启动kubelet即可
[root@k8s-master ~]# systemctl start kubelet
[root@k8s-master ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Wed 2021-06-09 00:29:53 PDT; 6s ago
Docs: http://kubernetes.io/docs/
Main PID: 66229 (kubelet)
Tasks: 18
Memory: 46.0M
CGroup: /system.slice/kubelet.service
└─66229 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/l...
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.203161 66229 configmap.go:195] Couldn't get configMap default/suanpan-configmap: could...condition
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.203904 66229 configmap.go:195] Couldn't get configMap xuelang/user-center-configs-5g9m...condition
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.204045 66229 nestedpendingoperations.go:267] Operation for "\"kubernetes.io/configmap/...(duration
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.204097 66229 secret.go:194] Couldn't get secret xuelang/default-token-r25q5: couldn't ...condition
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.204244 66229 nestedpendingoperations.go:267] Operation for "\"kubernetes.io/secret/41d...65617108
Jun 09 00:29:57 k8s-master kubelet[66229]: E0609 00:29:57.204612 66229 nestedpendingoperations.go:267] Operation for "\"kubernetes.io/configmap/...durationB
Jun 09 00:29:58 k8s-master kubelet[66229]: E0609 00:29:58.723928 66229 configmap.go:195] Couldn't get configMap default/suanpan-configmap: could...condition
Jun 09 00:29:58 k8s-master kubelet[66229]: E0609 00:29:58.724400 66229 nestedpendingoperations.go:267] Operation for "\"kubernetes.io/configmap/...durationB
Jun 09 00:29:58 k8s-master kubelet[66229]: E0609 00:29:58.736709 66229 secret.go:194] Couldn't get secret default/suanpan-admin-token-rlq9w: cou...condition
Jun 09 00:29:58 k8s-master kubelet[66229]: E0609 00:29:58.738364 66229 nestedpendingoperations.go:267] Operation for "\"kubernetes.io/secret/a0b...m=+5.7982
Hint: Some lines were ellipsized, use -l to show in full.
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.73.131 Ready master 47d v1.13.0
[root@k8s-master ~]# curl 192.168.73.131
Found. Redirecting to /web[root@k8s-master ~]#
FAQ-5)kubelet无法启动,提示不支持swap
 可能原因1:节点交换空间未关闭(k8s不支持在swap上运行)
可能原因1:节点交换空间未关闭(k8s不支持在swap上运行)
解决办法1:
- 关闭系统交换空间:swapoff -a && sed -i '/ swap / s/^(.*)$/#\1/g' /etc/fstab
- 禁用k8s调用swap,添加配置文件/etc/default/kubelet:
KUBELET_EXTRA_ARGS="--fail-swap-on=false --node-ip=10.29.5.124"
FAQ-6)Flannel无法启动,提示没有匹配的网络接口
 可能原因1:节点的网卡名称与flannel部署配置不匹配
可能原因1:节点的网卡名称与flannel部署配置不匹配
解决办法1:更改节点网卡名称,重启网卡,删除节点flannel相关pod即可。
vim /etc/sysconfig/network-scripts/ifcfg-team1(根据实际网卡来定)
systemctl restart network
kubectl -n kube-system delete pod kube-flannel_pod_name
 解决办法2:修改flannel.yaml配置后重新部署flannel,一种是添加多个网卡名称,一种是使用正则匹配。
解决办法2:修改flannel.yaml配置后重新部署flannel,一种是添加多个网卡名称,一种是使用正则匹配。
containers:
- name: kube-flannel
image: registry.cn-shanghai.aliyuncs.com/gcr-k8s/flannel:v0.10.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens32
- --iface=eth0
#- --iface-regex=eth*|ens*
FAQ-7)Pod状态一直处于ContainerCreating,提示runtime创建失败

 可能原因1:系统内存不足导致(可能节点上部署了其他服务,导致k8s无法检测出内存问题)
可能原因1:系统内存不足导致(可能节点上部署了其他服务,导致k8s无法检测出内存问题) 解决办法1:清理节点上非k8s集群内的其他服务,保持节点资源完全在k8s空间范围内,然后重启docker
解决办法1:清理节点上非k8s集群内的其他服务,保持节点资源完全在k8s空间范围内,然后重启docker
FAQ-8)修改daemon.json文件后,docker无法启动
 可能原因1:daemon.json文件格式错误
可能原因1:daemon.json文件格式错误
解决办法1:使用在线json校验工具测试一下
FAQ-9)算盘服务正常,无法拖入组件
可能原因1:minio缺少组件文件
解决办法:向minio环境拷贝缺少的data文件
可能原因2:服务器时间偏差
 解决办法:算盘服务器进行时间同步,安装时间同步服务:https://zhuanlan.zhihu.com/p/156757418
解决办法:算盘服务器进行时间同步,安装时间同步服务:https://zhuanlan.zhihu.com/p/156757418
FAQ-10)导入项目报错,export接口出现connect ETIMEOUT错误
 原因:算盘已知问题,服务器故障导致suanpan-web dns问题
原因:算盘已知问题,服务器故障导致suanpan-web dns问题
解决措施:重启suanpan-web,kubectl delete po [suanpan-web]
FAQ-11)服务器异常重启之后kube-dns异常
kubectl get pods --all-namespaces kubectl describe pod coredns-66bff467f8-kx4ck -n kube-system
kubectl describe pod coredns-66bff467f8-kx4ck -n kube-system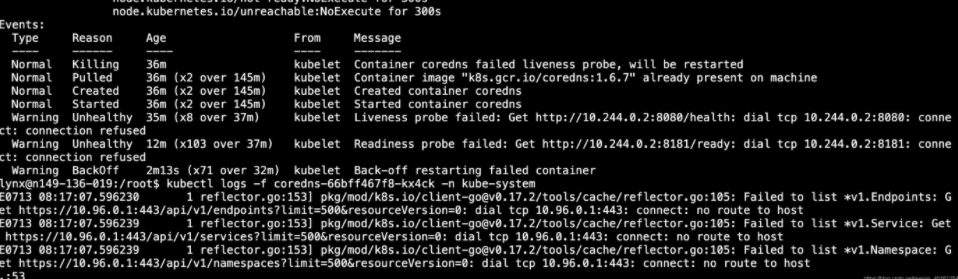 kubectl logs -f coredns-66bff467f8-kx4ck -n kube-system
kubectl logs -f coredns-66bff467f8-kx4ck -n kube-system 解决方法:
解决方法:
systemctl stop kubelet
systemctl stop docker
iptables --flush
iptables -tnat --flush
systemctl start docker
systemctl start kubelet
FAQ-12)服务器异常重启之后pod一直处于Terminating
 一般来说k8s会自动恢复,但有时也会出现容器假死,无法恢复情况,可以尝试重启节点kubelet或者docker
一般来说k8s会自动恢复,但有时也会出现容器假死,无法恢复情况,可以尝试重启节点kubelet或者docker
systemctl restart kubelet
systemctl restart docker
FAQ-13)dial tcp 10.96.0.1:443: connect: no route to host
可能原因1:kube-dns无法正常运行,这很有可能是iptables错乱了
解决办法1:参考【FAQ-11】
可能原因2:开启了防火墙,正常可以在初始化集群的时候看到告警提示
解决办法2:关闭防火墙 systemctl stop firewalld && systemctl disable firewalld
FAQ-14)Could not get lock /var/lib/dpkg/lock-frontend

mv /var/lib/dpkg/lock-frontend /var/lib/dpkg/lock-frontend.bak
mv /var/lib/dpkg/lock /var/lib/dpkg/lock.bak
FAQ-15)kube-controller和kube-scheduler异常
 这种情况一般都是服务器异常重启之后,k8s原生服务没处理好 ,偶先的问题,重启kubelet即可
这种情况一般都是服务器异常重启之后,k8s原生服务没处理好 ,偶先的问题,重启kubelet即可
(还有可能就是服务器资源被吃完,导致k8s集群服务收到影响)
top
systemctl restart kubelet

FAQ-16)container runtime 状态异常,导致k8s异常
 一般来说如果k8s服务全部异常,肯定是底层容器出问题了,此时重启docker和kubelet即可
一般来说如果k8s服务全部异常,肯定是底层容器出问题了,此时重启docker和kubelet即可
systemctl restart docker && systemctl restart kubelet
FAQ-17)minio启动失败“ERROR Unable to initialize config system...”
 这是由于minio版本过低,无法兼容高版本的minio生成的数据格式,更新minio镜像即可。
这是由于minio版本过低,无法兼容高版本的minio生成的数据格式,更新minio镜像即可。
>>>minio没有启动成功,会导致设置bucket失败:
FAQ-18)Flannel启动失败“Init:RunContainerError”
Events:error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded 从截图不难看出启动失败原因是OOMKilled,扩大Flannel资源即可,
从截图不难看出启动失败原因是OOMKilled,扩大Flannel资源即可,
kubectl -n kube-system edit ds kube-flannel-ds
spec.containers.resources.limits.memory
FAQ-19)minio请求提示过期
 检查服务器时间、Minio时间、客户端时间和应用服务时间(这里是我们的suanpan-web)—— 同步时间即可
检查服务器时间、Minio时间、客户端时间和应用服务时间(这里是我们的suanpan-web)—— 同步时间即可
查看接口信息可以得知有效期是60秒,但是实际应用服务比客户端时间慢60秒以上,所以导致一致请求过期。
FAQ-20)docker启动容器失败(getting the final child's pid from pipe caused eof unknown)
 此问题是因为系统内核pid达到限制,同时docker也有可能会出问题。
此问题是因为系统内核pid达到限制,同时docker也有可能会出问题。 可以扩大pid数
可以扩大pid数
echo "kernel.pid_max=1000000" >> /etc/sysctl.conf; sysctl -p
如果还是不行,则需要重启systemd和docker了(重启systemd可以尝试systemctl daemon-reexec)
systemctl daemon-reload && systemctl restart docker
解决方案来源:https://github.com/moby/moby/issues/40835

 /etc/sysctl.conf 添加,删除ConatinerCeating Pod
/etc/sysctl.conf 添加,删除ConatinerCeating Pod 
FAQ-21)kubelet启动失败(listen tcp [::1]:0: bind: cannot assign requested address)
 这是由于 /etc/hosts缺少ipv4回环地址,导致解析到了ipv6上了,加上即可
这是由于 /etc/hosts缺少ipv4回环地址,导致解析到了ipv6上了,加上即可
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
FAQ-22)Pod启动失败(failed to set bridge addr: "cni0" already has an IP address...)
Warning FailedCreatePodSandBox 3m18s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "1506a90c486e2c187e21e8fb4b6888e5d331235f48eebb5cf44121cc587a6f05" network for pod "ds-d58vg": networkPlugin cni failed to set up pod "ds-d58vg_kube-system" network: failed to set bridge addr: "cni0" already has an IP address different from 10.244.2.1/24
Normal SandboxChanged 3m1s (x12 over 4m13s) kubelet Pod sandbox changed, it will be killed and re-created.
Warning FailedCreatePodSandBox 2m59s (x4 over 3m14s) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "a8dc84257ca6f4543c223735dd44e79c1d001724a54cd20ab33e3a7596fba5c9" network for pod "ds-d58vg": networkPlugin cni failed to set up pod "ds-d58vg_kube-system" network: failed to set bridge addr: "cni0" already has an IP address different from 10.244.2.1/24
这是由于cni0网卡地址与flannel地址不一致导致。
ifconfig cni0
cat /run/flannel/subnet.env
重置节点,删除cni0网卡,重新加入集群即可。(或者尝试删除cni0网卡,并重启flannel和dns pod)
ifconfig cni0 down
ip link delete cni0
FAQ-23)Pod启动失败(open /var/lib/docker/……/mount-id: no such file or directory)
 一般是docker目录变更导致,而docker-root默认值为/var/lib/docker,修改为正确的目录后,重启kubelet问题解决(或者直接给kubelet增加了参数:--docker-root )
一般是docker目录变更导致,而docker-root默认值为/var/lib/docker,修改为正确的目录后,重启kubelet问题解决(或者直接给kubelet增加了参数:--docker-root )
FAQ-24)k8s集群调度非常卡
查看k8s基础服务状态,特别是dns是否出现重启,如果dns异常就导致集群访问受阻,从而影响调度。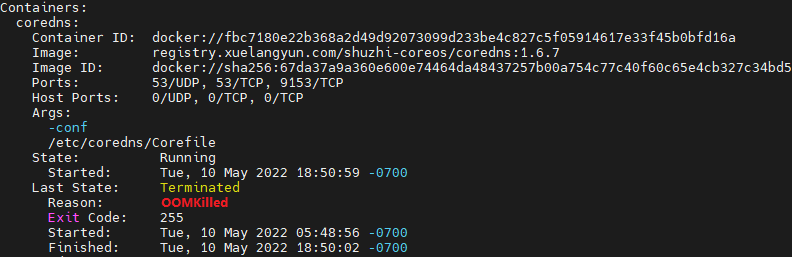 这里是因为corndns发生oom了,可以调大resources.limit.memory
这里是因为corndns发生oom了,可以调大resources.limit.memory
kubectl -n kube-system edit deploy coredns
FAQ-25)metrics-server无法收集到集群资源(no metrics known for pod)


 参数官网要求,可知kubelet需要配置以下参数:
参数官网要求,可知kubelet需要配置以下参数:
--anonymous-auth=false #(default true)
--authorization-mode="Webhook" #(default "AlwaysAllow")
注意:这里 authorization-mode 一些云服务要求必须是AlwaysAllow,否则kubelet可能访问异常。
FAQ-26)kube-flannel-ds 部分节点启动失败(对应 pod 状态为 INIT:0/1)
更新证书后部分节点的 kube-flannel-ds 节点没有正常启动,查看对应 pod 信息  依照信息反馈为对应节点没有 pid 可用,依照 FAQ-20 检查系统最大 pid 数(可通过 ulimit -a 命令查看 max user processes 的值)并在对应节点通过 docker ps -a 命令查看相关 flannel 容器运行情况,发现对应容器以大约一秒一个的速度进行创建,但容器状态为 created,且系统 pid 充裕。
依照信息反馈为对应节点没有 pid 可用,依照 FAQ-20 检查系统最大 pid 数(可通过 ulimit -a 命令查看 max user processes 的值)并在对应节点通过 docker ps -a 命令查看相关 flannel 容器运行情况,发现对应容器以大约一秒一个的速度进行创建,但容器状态为 created,且系统 pid 充裕。
可以直接重启节点服务器的 docker 服务,观察 pod 是否恢复正常。
重启过后,若 flannel 的节点 pod 依旧未恢复正常,且有其他节点的 flannel 运行正常,可以删除对应节点的 pod,让其重新生成,随恢复正常。
FAQ-27)检查集群健康状态,提示无法连接10251/10252端口
这种情况是因为kube-controller-manager.yaml和kube-scheduler.yaml 里面配置了默认端口0
root@k8s-21 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
[root@k8s-21 manifests]# sed -i "s/- --port=0/#- --port=0/g" /etc/kubernetes/kube-controller-manager.yaml
[root@k8s-21 manifests]# sed -i "s/- --port=0/#- --port=0/g" /etc/kubernetes/kube-scheduler.yaml
[root@k8s-21 manifests]# systemctl restart kubelet
[root@k8s-21 manifests]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
FAQ-28)服务器无法访问,提示“possible memory allocation deadlock……”
 升级系统内核版本,然后重启服务器即可
升级系统内核版本,然后重启服务器即可
yum install -y kernel-3.10.0-1160.el7