一对一分类(OneVsOneClassifier)
| 组件名称 | 一对一分类(OneVsOneClassifier) | ||
|---|---|---|---|
| 工具集 | 机器学习/分类/一对一分类(OneVsOneClassifier) | ||
| 组件作者 | 雪浪云-燕青 | ||
| 文档版本 | 1.0 | ||
| 功能 | 一对一分类(OneVsOneClassifier)算法 | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器。构造多分类器可以采用直接法或者间接法。 但是若采取直接法即SVM直接在目标函数上进行修改的话,将多个分类面的参数求解合并到一个最优化问题上,显然难度太大,其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中。
一对一(one-versus-one,简称OVO SVMs或者pairwise)其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就要设计k(k-1)/2个SVM。
当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm(一个好用的包)中的多类分类就是根据这个方法实现的
假设有四类A,B,C,D四类。在训练的时候我选择A,B; A,C; A,D; B,C; B,D;C,D所对应的向量作为训练集(4X3/2=6),然后得到六个训练结果,在测试的时候,把对应的向量分别对六个结果进行测试,然后采取投票形式,最后得到一组结果。
评价:这种方法虽然好,但是当类别很多的时候,model的个数是n*(n-1)/2,代价还是相当大的。与一对多相比不会有样本不属于任何一类的情形出现,但是复杂度变大了。
组件
- 组件图:
输入桩
支持单个csv文件输入。
输入端子1
- 端口名称:训练数据
- 输入类型:Csv文件
- 功能描述: 输入用于训练的数据
输入端子2
- 端口名称:输入模型
- 输入类型:sklearn模型
- 功能描述: 分类模型文件
输出桩
支持sklearn模型输出。
输出端子1
- 端口名称:输出模型
- 输出类型:sklearn模型
- 功能描述: 输出训练好的模型用于预测
参数配置
并行度
- 功能描述:训练时的并行度
- 必选参数:否
- 默认值:(无)
需要训练
- 功能描述:该模型是否需要训练,默认为需要训练。
- 必选参数:是
- 默认值:true
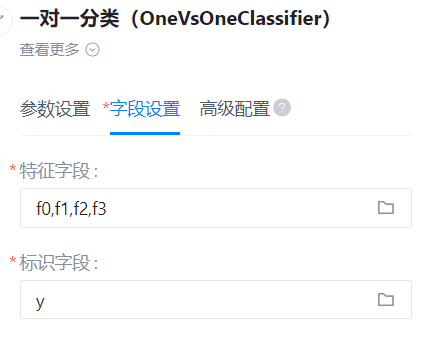
特征字段
- 功能描述:特征字段
- 必选参数:是
- 默认值:(无)
识别字段
- 功能描述:识别字段
- 必选参数:是
- 默认值:(无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点
测试用例
模板
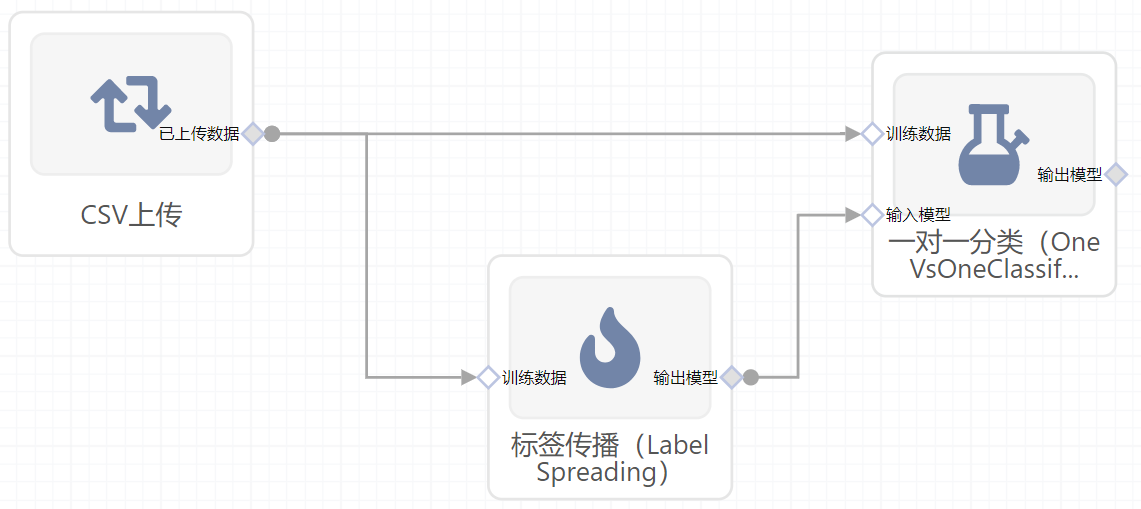
右面板配置
- 参数设置:
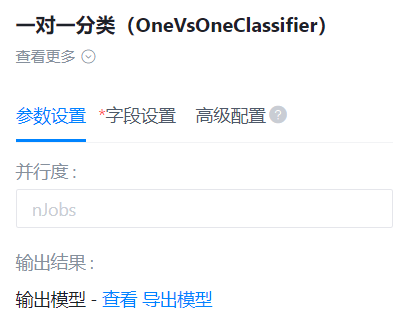
- 字段设置:

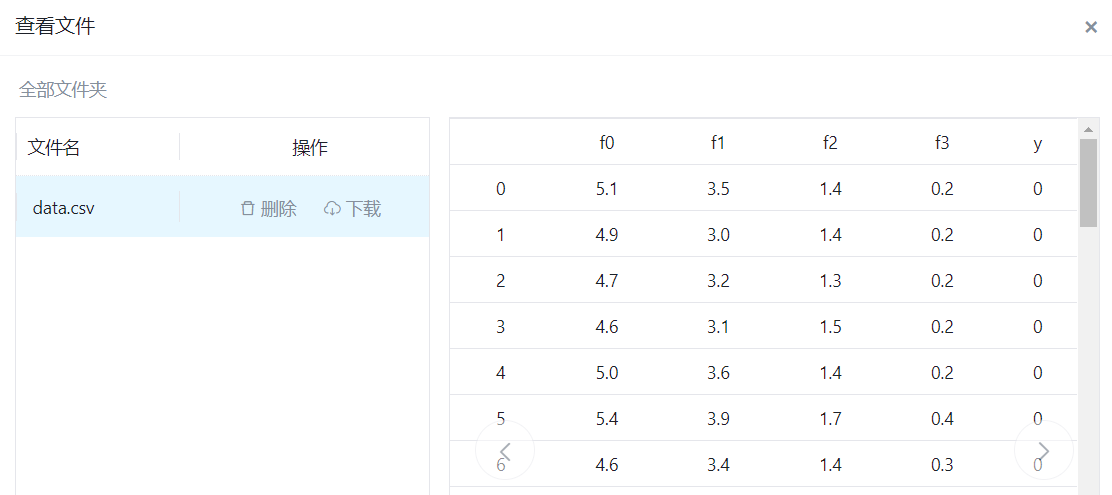
输入的数据:
输出的结果: