线性支持向量机回归(LinearSVR)
| 组件名称 | 线性支持向量机回归(LinearSVR) | ||
|---|---|---|---|
| 工具集 | 机器学习 | ||
| 组件作者 | 雪浪云-墨文 | ||
| 文档版本 | 1.0 | ||
| 功能 | 线性支持向量机回归(LinearSVR) | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
在机器学习中,支持向量机(SVMs,也称为支持向量网络)是一种有关联学习算法的监督学习模型,支持分类和回归问题的数据建模。给定一组训练数据,每个样本属于一个或其他类别,用支持向量机算法构建并训练一个模型,将新样本分配到一个类别,使它成为一个非概率性二分类器。支持向量机模型是将样本表示为空间中的点,并将其映射,以便将不同类别的样本之间的间距尽可能大。然后,新的样本被映射到相同的空间中,并根据它们所处的位置,预测它们属于某个类别。
除了执行线性分类,支持向量机还可以通过使用核线方程有效地执行非线性分类,隐式地将它们的输入映射到高维特征空间。
当数据没有标记时,监督学习是不可能的,需要一种无监督学习方法,通过无监督学习试图找到数据到类别的自然聚类,然后将新数据映射到这些形成的类别。支持向量聚类算法是由Hava Siegelmann和Vladimir Vapnik共同创建的,它利用支持向量的统计量对未标注的数据进行分类,是工业应用中应用最广泛的聚类算法之一。
支持向量机也可以作为回归方法,保持算法的所有主要特征(最大边缘算法)。支持向量回归(SVR)使用与支持向量机相同的原则进行分类,只有一些细微的差异。首先,因为输出是一个连续值,所以很难预测,因为它有无限种可能性。在回归的情况下,容忍度(epsilon)被设置为支持向量机的近似值,算法将更加复杂。然而,其主要思想始终是相同的:为了最小化误差,使超平面的类别间距最大化,但是部分误差是可以容忍的。
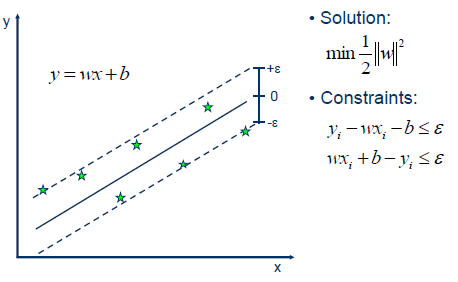
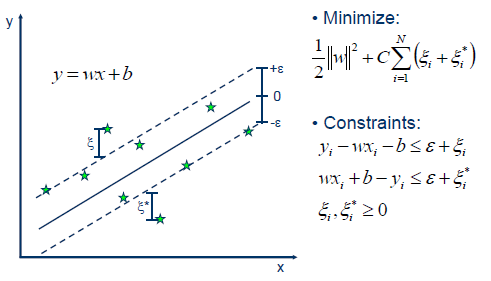
Linear SVR
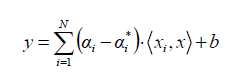
输入桩
支持单个csv文件输入。
输入端子1
- 端口名称:训练数据
- 输入类型:Csv文件
- 功能描述: 输入用于训练的数据
输出桩
支持sklearn模型输出。
输出端子1
- 端口名称:输出模型
- 输出类型:sklearn模型
- 功能描述: 输出训练好的模型用于预测
参数配置
epsilon
- 功能描述:epsilon-insensitive 损失函数中的Epsilon参数。
- 必选参数:是
- 默认值:0
tol
- 功能描述:early stop的容忍度。
- 必选参数:是
- 默认值:0.00001
C
- 功能描述:误差项的惩罚参数C。
- 必选参数:是
- 默认值:1
loss
- 功能描述:指定损失函数,squared_epsilon_insensitive和epsilon_insensitive可选。
- 必选参数:是
- 默认值:epsilon_insensitive
Fit Intercept
- 功能描述:是否计算该模型的截距。
- 必选参数:是
- 默认值:true
Intercept Scaling
- 功能描述:为了减少正则化对合成特征权重(截距)的影响,必须增加Intercept Scaling。
- 必选参数:是
- 默认值:1
dual
- 功能描述:选择求解对偶优化问题或原优化问题的算法。
- 必选参数:是
- 默认值:true
verbose
- 功能描述:是否输出详细信息。
- 必选参数:是
- 默认值:0
Random State
- 功能描述:是随机数生成器使用的种子。
- 必选参数:是
- 默认值:0
Max Iter
- 功能描述:要运行的最大迭代数。
- 必选参数:是
- 默认值:1000
需要训练
- 功能描述:该模型是否需要训练,默认为需要训练。
- 必选参数:是
- 默认值:true
特征字段
- 功能描述: 特征字段
- 必选参数: 是
- 默认值: (无)
识别字段
- 功能描述: 目标字段
- 必选参数: 是
- 默认值: (无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点
