ExtraTrees回归(ExtraTreesRegressor)使用文档
| 组件名称 | ExtraTrees回归(ExtraTreesRegressor) | ||
|---|---|---|---|
| 工具集 | 机器学习/回归/ExtraTrees回归(ExtraTreesRegressor) | ||
| 组件作者 | 雪浪云-燕青 | ||
| 文档版本 | 1.0 | ||
| 功能 | ExtraTrees回归(ExtraTreesRegressor) | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
ET或Extra-Trees(Extremely randomized trees,极端随机树)是由PierreGeurts等人于2006年提出。该算法与随机森林算法十分相似,都是由许多决策树构成。但该算法与随机森林有两点主要的区别:
- 随机森林应用的是Bagging模型,而ET是使用所有的训练样本得到每棵决策树,也就是每棵决策树应用的是相同的全部训练样本;
- 随机森林是在一个随机子集内得到最佳分叉属性,而ET是完全随机的得到分叉值,从而实现对决策树进行分叉的。
对于第2点的不同,我们再做详细的介绍。我们仅以二叉树为例,当特征属性是类别的形式时,随机选择具有某些类别的样本为左分支,而把具有其他类别的样本作为右分支;当特征属性是数值的形式时,随机选择一个处于该特征属性的最大值和最小值之间的任意数,当样本的该特征属性值大于该值时,作为左分支,当小于该值时,作为右分支。这样就实现了在该特征属性下把样本随机分配到两个分支上的目的。然后计算此时的分叉值(如果特征属性是类别的形式,可以应用基尼指数;如果特征属性是数值的形式,可以应用均方误差)。遍历节点内的所有特征属性,按上述方法得到所有特征属性的分叉值,我们选择分叉值最大的那种形式实现对该节点的分叉。从上面的介绍可以看出,这种方法比随机森林的随机性更强。
对于某棵决策树,由于它的最佳分叉属性是随机选择的,因此用它的预测结果往往是不准确的,但多棵决策树组合在一起,就可以达到很好的预测效果。
当ET构建好了以后,我们也可以应用全部的训练样本来得到该ET的预测误差。这是因为尽管构建决策树和预测应用的是同一个训练样本集,但由于最佳分叉属性是随机选择的,所以我们仍然会得到完全不同的预测结果,用该预测结果就可以与样本的真实响应值比较,从而得到预测误差。如果与随机森林相类比的话,在ET中,全部训练样本都是OOB样本,所以计算ET的预测误差,也就是计算这个OOB误差。
在这里,我们仅仅介绍了ET算法与随机森林的不同之处,ET算法的其他内容(如预测、OOB误差的计算)与随机森林是完全相同的,具体内容请看关于随机森林的介绍。
输入桩
支持单个csv文件输入。
输入端子1
- 端口名称:训练数据
- 输入类型:Csv文件
- 功能描述: 输入用于训练的数据
输出桩
支持sklearn模型输出。
输出端子1
- 端口名称:输出模型
- 输出类型:sklearn模型
- 功能描述: 输出训练好的模型用于预测
参数配置
树的数量
- 功能描述:树的数量
- 必选参数:是
- 默认值:10
质量函数
- 功能描述:用于计算分割质量的函数。
- 必选参数:是
- 默认值:mse
节点拆分策略
- 功能描述:用于在每个节点上选择拆分的策略。
- 必选参数:是
- 默认值:best
树的最大深度
- 功能描述:树的最大深度
- 必选参数:否
- 默认值:(无)
分割内部节点所需的最小样本数
- 功能描述:分割内部节点所需的最小样本数
- 必选参数:是
- 默认值:2
叶节点上所需的最小样本数
- 功能描述:叶节点上所需的最小样本数
- 必选参数:是
- 默认值:1
叶节点(所有输入样本)所需权值之和的最小加权分数
- 功能描述:叶节点(所有输入样本)所需权值之和的最小加权分数
- 必选参数:是
- 默认值:0
在寻找最佳分割时要考虑的特征数量
- 功能描述:在寻找最佳分割时要考虑的特征数量
- 必选参数:是
- 默认值:auto
Random State
- 功能描述:随机种子。
- 必选参数:否
- 默认值:(无)
最小杂志减少值
- 功能描述:如果这个分裂导致杂质的减少大于或等于这个值,一个节点就会分裂。
- 必选参数:是
- 默认值:0
最大叶节点数
- 功能描述:最大叶节点数
- 必选参数:否
- 默认值:(无)
CCP Alpha
- 功能描述:用于最小成本-复杂性修剪的复杂性参数
- 必选参数:是
- 默认值:0
最大样本数
- 功能描述:用于训练的样本数
- 必选参数:否
- 默认值:(无)
并行度
- 功能描述:训练时使用的CPU核数
- 必选参数:否
- 默认值:(无)
需要训练
- 功能描述:该模型是否需要训练,默认为需要训练。
- 必选参数:是
- 默认值:true
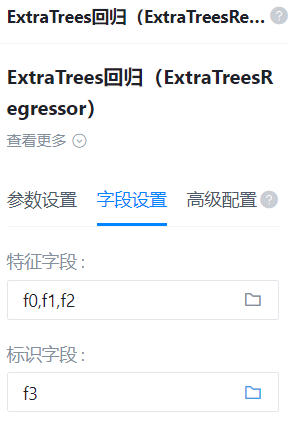
特征字段
- 功能描述:特征字段
- 必选参数:是
- 默认值:(无)
识别字段
- 功能描述:识别字段
- 必选参数:是
- 默认值:(无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点

测试用例
模板
右面板配置
查看结果