多分类评估(MultiClass)使用文档
| 组件名称 | 多分类评估(MultiClass) | ||
|---|---|---|---|
| 工具集 | 机器学习/算法设计/机器学习/评估/多分类评估(MultiClass) | ||
| 组件作者 | 雪浪云-燕青 | ||
| 文档版本 | 1.0 | ||
| 功能 | 多分类评估(MultiClass)算法 | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
多分类评估是指基于分类模型的预测结果和原始结果,评估多分类算法模型的优劣性,从而输出评估指标(例如Accuracy、Kappa及F1-Score。
在机器学习任务中,为了较为全面地评价一个分类模型classifier的性能好坏,并且方便地比较不同classifier之间的优劣,我们总是希望通过使用特定的评判指标metrics来为classifer给出一个直观又准确的评分。
对于类别较少的分类问题,如二分类、三分类来说,accuracy是一个比较常用且有效的评判指标;如果要更全面地研究模型的性能,引入f1-score来综合考虑模型的precision和recall能力;甚至是细致地研究其中每一个类别的precision、recall指标等都是比较容易实现的。
然而,对于非常多类别的(如我用到的数据集是500+类)分类任务,想要细致地比较不同的classifer在每个具体类别上的效果是非常困难的,因为通常而言一个模型会在某一些类别上表现良好,而在另一些类别上另一个模型又会有更好的表现,很难综合评价模型的性能;另一方面,使用简单的单个数值的评价指标如accuracy等会因为数据集中严重的类别不均衡问题(在超过100类的真实数据集中大多都有严重的类别不均衡)而具有严重的偏见性。
输入桩
支持单个csv文件输入。
输入端子1
- 端口名称:预测后数据
- 输入类型:Csv文件
- 功能描述: 输入预测后的数据
输出桩
支持json文件输出。
输出端子1
- 端口名称:评估结果
- 输出类型:json文件
- 功能描述: 输出评估的结果
参数配置
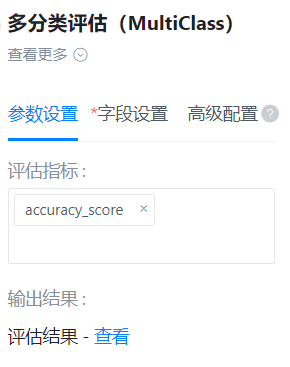
评估指标
- 功能描述:选择多分类评估的指标,有以下指标可以选择:f1_score、accuracy_score、precision_score、recall_score、hamming_loss、zero_one_loss、jaccard_score
- 必选参数:是
- 默认值:f1_score
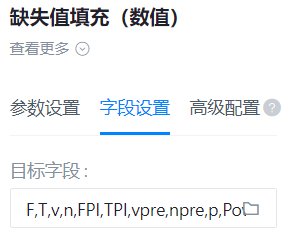
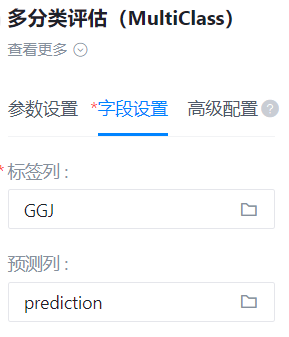
标签列
- 功能描述:标签列
- 必选参数:是
- 默认值:(无)
预测列
- 功能描述:预测列
- 必选参数:是
- 默认值:(无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点

测试用例
模板
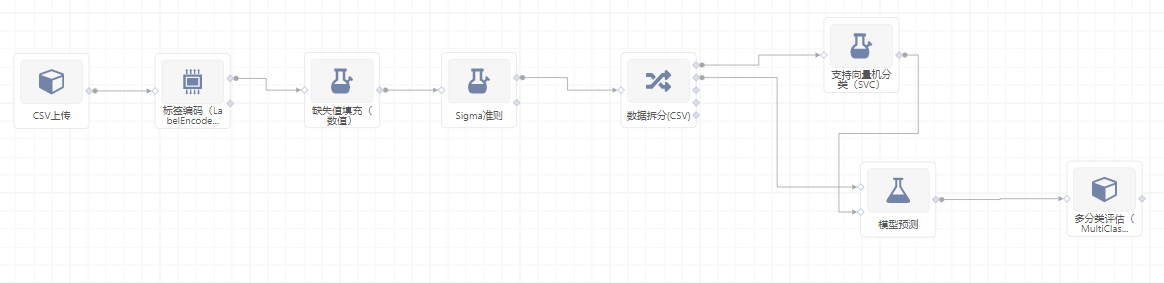
右面板配置

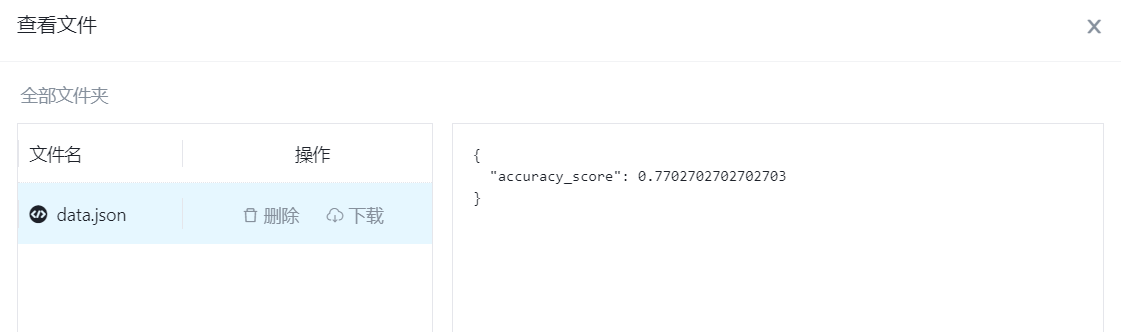
查看结果