概率校准曲线(CalibrationCurve)使用文档
| 组件名称 | 概率校准曲线(CalibrationCurve) | ||
|---|---|---|---|
| 工具集 | 机器学习/算法设计/机器学习/评估/概率校准曲线(CalibrationCurve) | ||
| 组件作者 | 雪浪云-燕青 | ||
| 文档版本 | 1.0 | ||
| 功能 | 概率校准曲线(CalibrationCurve) | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
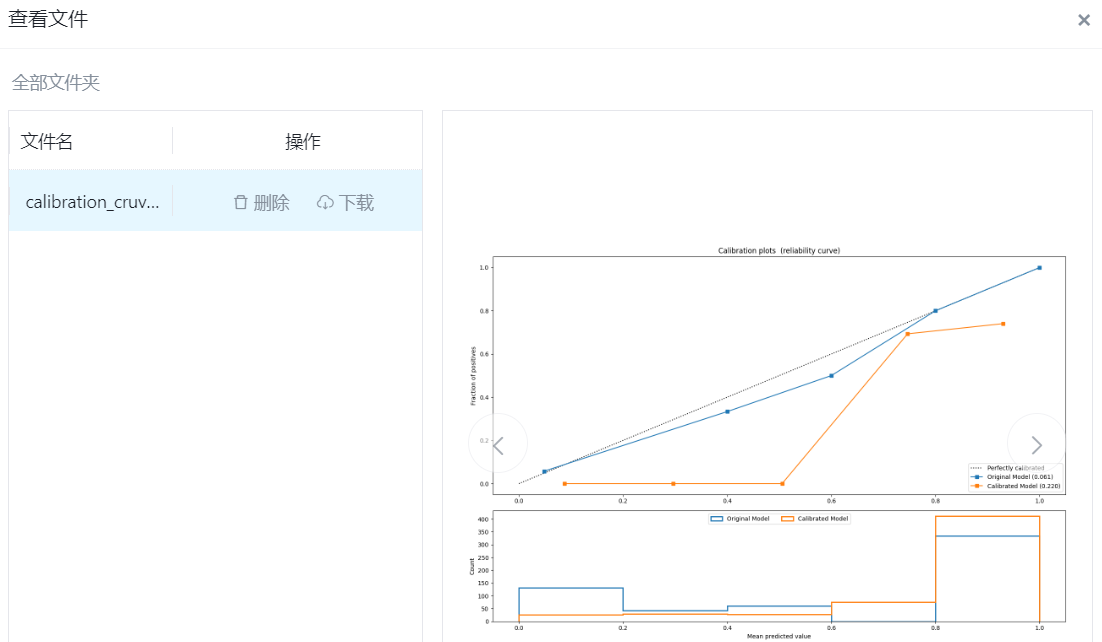
分类器输出的概率的意义表示的是样本属于某一个类别的置信度,比如样本预测概率为0.8,则按照概率的意义,100个输出概率为0.8的样本中应该有80个这样的样本的实际标签属于预测标签。然而实际上不同模型的预测概率都是有偏的。很多模型,尤其是数据进行上or下采样之后训练出来的模型,其预测的概率就已经失去了真实的概率意义了,而仅仅是保留了相对排序性,比如说不均衡问题里,少类样本(默认都标签为1)存在的概率大概0.1%,如果进行简单的上1:1的采样训练,则会发现模型预测少类样本的概率高达0.5以上,显然和真实的概率产生巨大的偏离。
逻辑回归本身是直接针对二元交叉熵进行优化的,简单来说就是让输出的概率尽量接近0和1,所以其本身训练的过程就是让预测概率尽量接近真实的标签,并且lr就是一个简单的单模,自然预测概率和真实概率的偏差很小,这个结论对于使用二元交叉熵的nn一样适用。
输入桩
支持Csv、sklearn文件输入。
输入端子1
- 端口名称:训练数据
- 输入类型:Csv文件
- 功能描述:输入需要训练的数据
输入端子2
- 端口名称:原始模型
- 输入类型:sklearn文件
- 功能描述:输入原始模型
输入端子3
- 端口名称:校准模型
- 输入类型:sklearn文件
- 功能描述:输入校准模型
输出桩
支持image文件输出。
输出端子1
- 端口名称:校准曲线
- 输出类型:image文件
- 功能描述:输出校准曲线
参数配置
normalize
- 功能描述:是否归一化
- 必选参数:是
- 默认值:false
nBins
- 功能描述:目标数
- 必选参数:是
- 默认值:5
strategy
- 功能描述:校准策略,有以下策略可以选择:uniform、quantile
- 必选参数:是
- 默认值:uniform
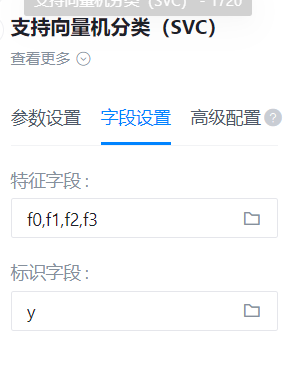
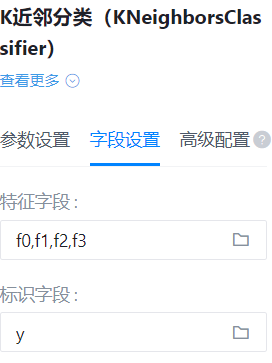
特征字段
- 功能描述:特征字段
- 必选参数:是
- 默认值:(无)
标识字段
- 功能描述:标识字段
- 必选参数:是
- 默认值:(无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点

测试用例
模板
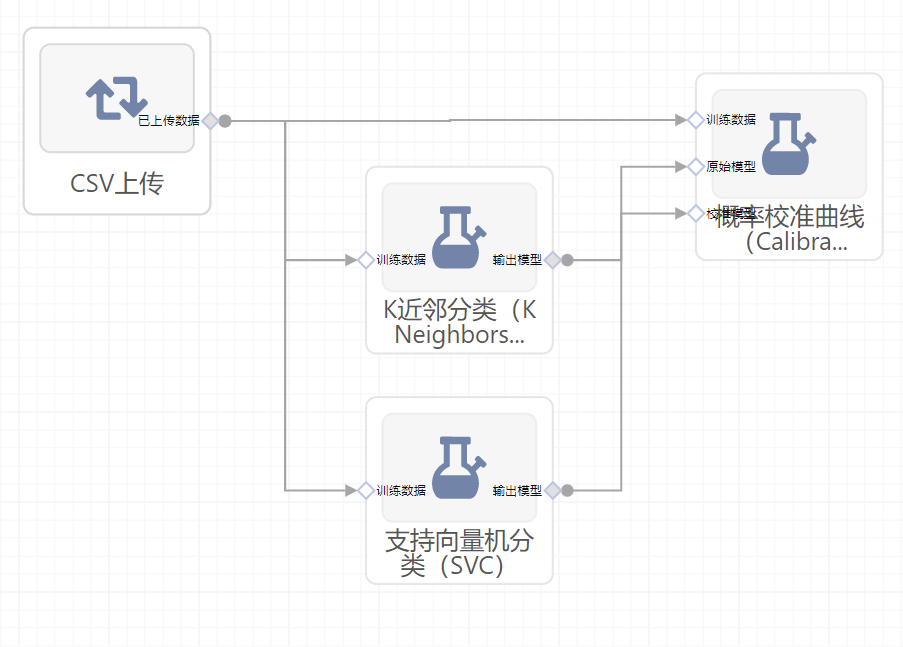
如图所示连接组件
右面板配置
各组件右面板如下图
查看结果