聚类评估(非监督)
| 组件名称 | 聚类评估(非监督) | ||
|---|---|---|---|
| 工具集 | 机器学习/评估/聚类评估(非监督) | ||
| 组件作者 | 雪浪云-燕青 | ||
| 文档版本 | 1.0 | ||
| 功能 | 聚类评估(非监督)算法 | ||
| 镜像名称 | ml_components:3 | ||
| 开发语言 | Python |
组件原理
我们需要意识到聚类分析本身是一项试探性的数据分析工作,即我们并不知道什么是最优的聚类结果(数据中甚至并不存在聚类模式),因此对于簇的质量的评估是一个尴尬的过程,我们自以为得出了高质量的簇,但是实际上原数据可能只是随机分布的点。尽管如此,我们依然希望能够通过已有的信息尽可能判断得到的簇的质量,毕竟高质量的簇至少有较高高概率对应了某些聚类模式。
非监督:根据得出的簇的信息,来评估簇结构的优良性。通常来说非监督的度量由称为内部指标,主要是凝聚性和分离性,描述了簇内部和簇之间的质量,而脱离实际的外部信息。
对于划分的聚类,我们定义簇的有效性。簇的有效性可以指出的凝聚性,也可以指簇的分离性,其描述了聚类算法得出的簇的质量。一个有效的簇,应该具有较高的凝聚度或者较高的分离度。我们用所有簇的(加权)有效性的和来描述一个聚类的总有效性。以下分别从基于图的聚类技术和基于原型的聚类技术两个角度,去探讨什么是凝聚度和分离度。
在基于图的聚类技术中,我们将数据视作单独的点,点与点之间的邻近度用点之间的边的长度来表示。一个簇之内所有的点之间的边的长度的加权和,表示了这个簇的凝聚度。两个簇之间的点与点之间的边的长度的加权和,表示了这两个簇之间的分离度。
在基于原型的聚类技术中,我们将簇用原型来进行代表。一个簇内所有点到其原型的邻近度之和,表示了簇的凝聚度。两个簇的原型之间的距离,表示了这两个簇之间的分离度。额外的,单个簇的分离度度量可以用该簇原型到所有数据的总原型的邻近度描述。这是因为对于一个聚类,其总分离度与所有簇之间的相对分离度有直接关系,而总分离度又可以用所有簇原型到总原型邻近度表示。
组件
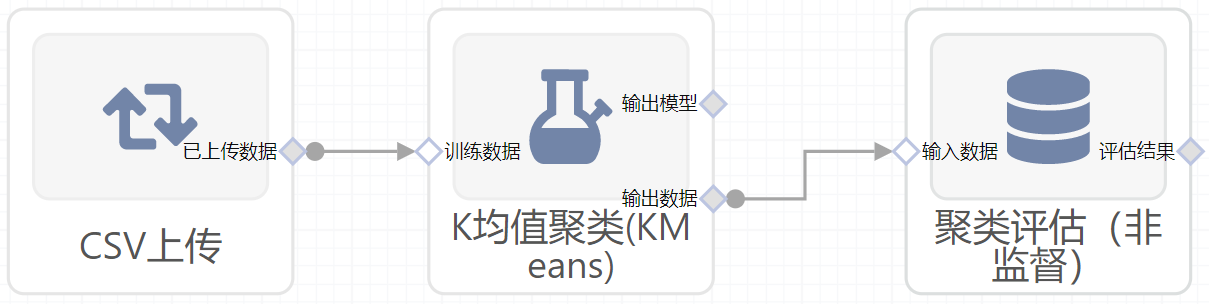
- 组件图:
输入桩
支持单个csv文件输入。
输入端子1
- 端口名称:输入数据
- 输入类型:Csv文件
- 功能描述:输入预测后的数据
输出桩
支持json文件输出。
输出端子1
- 端口名称:评估结果
- 输出类型:json文件
- 功能描述:输出评估的结果
参数配置
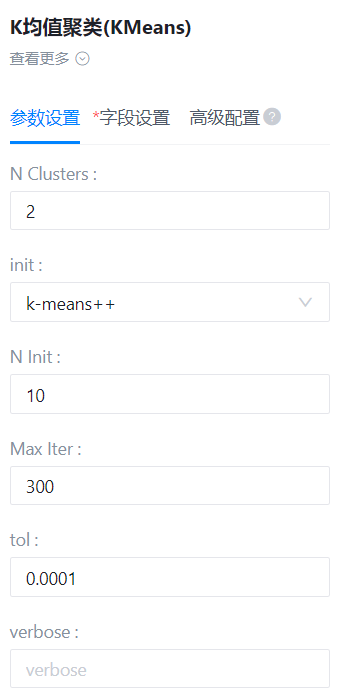
度量方法
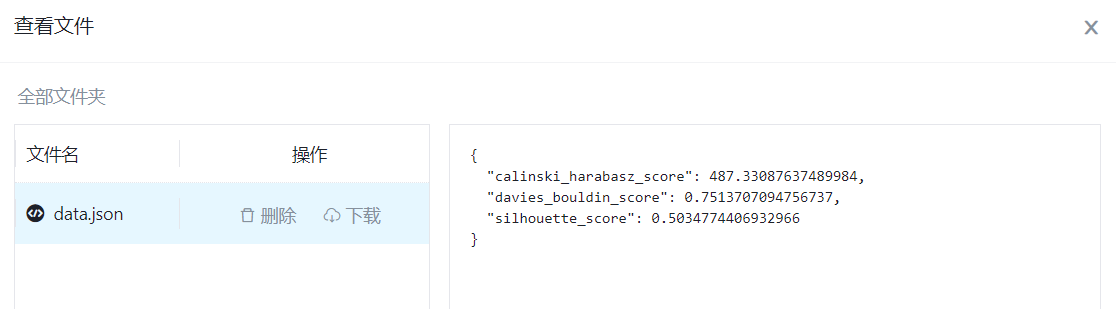
- 功能描述:选择聚类评估的指标,有以下指标可以选择:calinski_harabasz_score、davies_bouldin_score、v_measure_score、silhouette_score
- 必选参数:是
- 默认值:calinski_harabasz_score
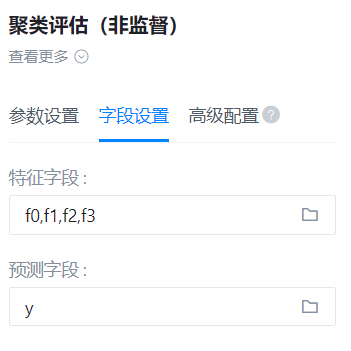
标签字段
- 功能描述:标签字段
- 必选参数:是
- 默认值:(无)
预测字段
- 功能描述:预测字段
- 必选参数:是
- 默认值:(无)
使用方法
- 将组件拖入到项目中
- 与前一个组件输出的端口连接(必须是csv类型)
- 点击运行该节点
测试用例
模板
右面板配置
- 参数设置:
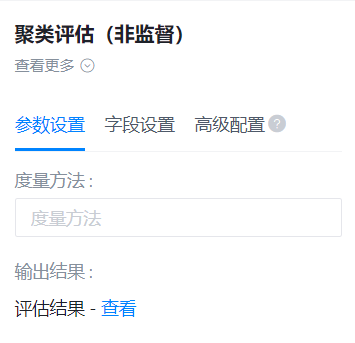
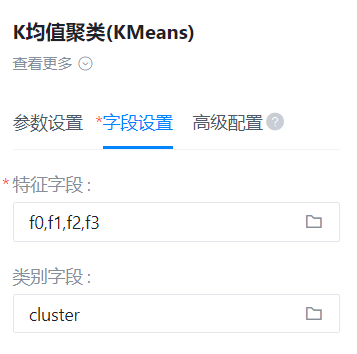
- 字段设置:
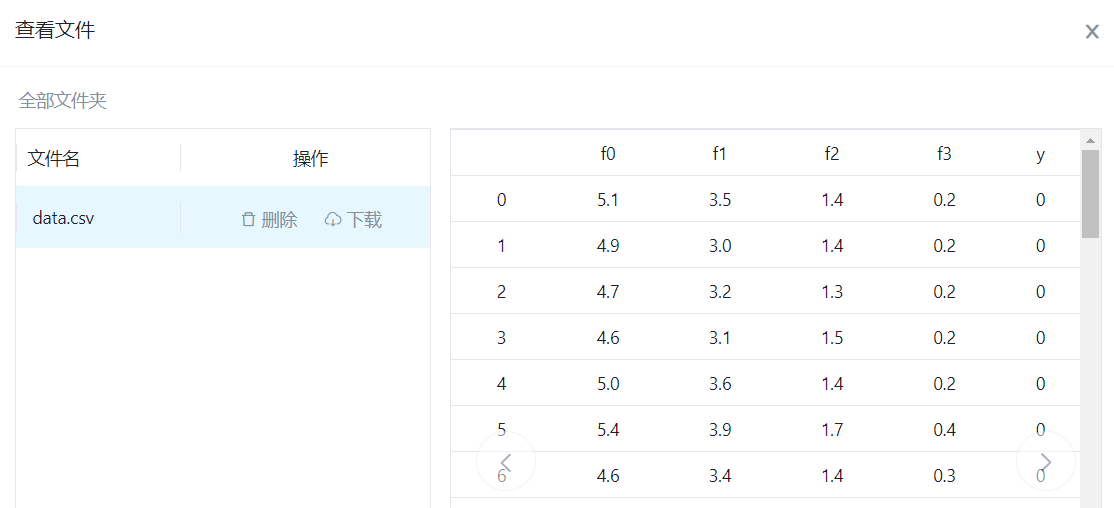
输入的数据:
输出的结果:
- 评估结果: