LSTM Network 回归模型
LSTM Network 回归模型
LSTM Network 长短期时间序列模型介绍
核心算法介绍:
传统的RNN神经网络:
RNN之所以称为循环神经网络,即“一个序列的当前输出与前面的输出是有相关性”。具体实质体现在后面层数的输入值要加入前面层的输出值,即隐藏层之间不再是不相连的而是有连接的。 展开的递归循环神经网络
展开的递归循环神经网络
在学习信息情况下,如果相关信息与所需信息之间的差距很小,则RNN可以学习使用过去的信息,表现出较好的训练能力,比如:我们试图预测“云在天空中”的最后一次“天空”,RNN模型就能非常容易的识别出来。但是,如果相关信息与所需要信息之间的距离相差过远时,RNN模型就会很难学习连接这些关系。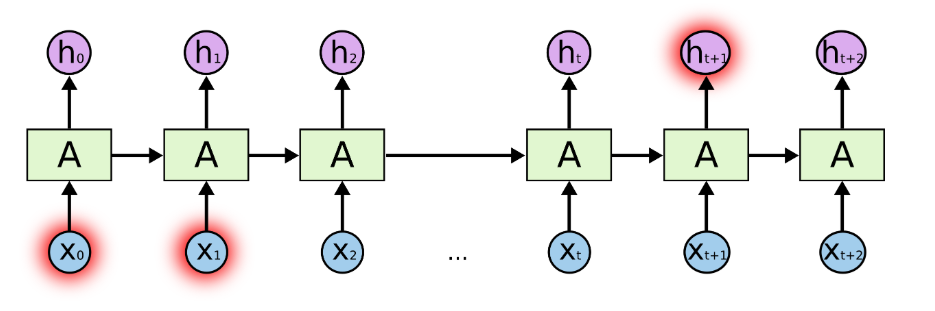 LSTM 神经网络:
LSTM 神经网络:
长短期时间序列模型(LSTM)是一种特殊的RNN,能够学习长期的依赖性。LSTM的优点就是能够明确旨在避免长期依赖性问题。它能够长时间记住信息,解决了RNN信息距离过长而丧失学习的能力的缺点。所有递归神经网络都具有具有神经网络重复模块链的形式。在标准的RNN中,该重复模块具有非常简单的结构,就是单一的tanh层。 标准RNN中的重复模块包含单个层
标准RNN中的重复模块包含单个层
同样LSTM也具有这种类似链的结构,但是重复模块缺失具有不同的结构,它们分别是传输层,遗忘门,输入门,输出门。 LSTM中的重复模块包含四个交互层
LSTM中的重复模块包含四个交互层
1.传输层
传输层水平贯穿图的顶部,直接沿着整个链运行,进行着一些次要的线性交互。从上图中我们可以看出,每个序列索引位置t时刻向前传播中除了和RNN一样具有隐藏状态h(t),还多了另一个隐藏状态,图中上面的横线我们一般称为细胞状态,记为C(t)。 2.遗忘门
2.遗忘门
遗忘门是以一定的概率控制是否遗忘上一层的隐藏细胞状态。图中我们可以看出输入的有上一序列的隐藏状态 h(t-1) 和本序列数据 x(t) ,通过激活函数sigmoid,得到遗忘门的输出 f(t) .由于sigmoid函数的输出 f(t) 是位于[0,1]之间,所以这里的输出 f(t) 就是代表了能否遗忘上一层隐藏细胞状态的概率。 该数字表达可以为: 其中 Wf , Uf , bf 分别为线性关系的权重和偏移值。
其中 Wf , Uf , bf 分别为线性关系的权重和偏移值。 3.输入门
3.输入门
输入门层决定我们在单元状态中存储哪些新的信息。其中有两部分组成,一部分称为“输入门层的sigmoid层”,这层决定我们将更新之前的哪些值,输出为 i(t),第二部分为“输入门层的tanh层”,这层决定我们创建新的候选值,输出为 a(t),最后结合两个创建状态进行更新。 该数学表达式可以为: 其中 Wi, Ui, bi, Wa, Ua, ba分别为线性关系的权重和偏移值。
其中 Wi, Ui, bi, Wa, Ua, ba分别为线性关系的权重和偏移值。 4.细胞状态更新
4.细胞状态更新
此过程是决定将旧的细胞状态C(t-1)更新至新的细胞状态C(t)。在这个过程中首先我们将ft乘以C(t-1)来决定是否忘记之前的事情。其次我们添加了 来决定我们需要更新多少新的状态值。即:
来决定我们需要更新多少新的状态值。即:
 5.输出门
5.输出门
输出门是决定我们要输出的内容。首先,先运行的是一个sigmoid层,决定输出的单元状态属于隐藏状态部分 h(t-1), 还是本序列数据部分 x(t).接着,运行的是tan层,将细胞状态 Ct 乘以sigmoid层的输出,从而获取我们所决定的部分。即:  同理其中的 Wo, Uo, bo分别为线性关系的权重和偏移值。
同理其中的 Wo, Uo, bo分别为线性关系的权重和偏移值。 Keras LSTM 算法模型:**
Keras LSTM 算法模型:**
LSTM模型构建:
1.首先初始化模型Sequential()
2.接着添加LSTM模型层架构,其中hiddenLayer代表为隐藏神经元个数,通俗易懂的解释可以为模型中每个sigmoid层或者tanh层。(注意:LSTM训练模型格式矩阵内容[samples,time_steps,features],简单的说就是[n,1,m]架构,即规定了多少特征输入,一个输出)
3.添加模型全连接层
4.编译模型,选择对应的损失函数和优化器,其中常用的损失函数是MSE,MAE–用于回归,binary-crossentropy–用于二值化分类,categorical-crossentropy–用于标签分类。优化的选择我们常用的自适应学习率优化算法 AdaGrad, AdaDelta,Adam。其他类型不建议使用。
model = Sequential()
model.add(LSTM(hiddenLayer, input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(Dense(1))model.compile(loss=loss, optimizer=optimizer, metrics=["accuracy"])
LSTM模型训练:
将设置好的LSTM模型进行训练,其中epochs为循环迭代的次数,batchsize即每次循环所走的分支数,validationdata即采用交叉验证的方式对数据进行验证
# Fit network
checkpointer = ModelCheckpoint(filepath=outputModel, verbose=1, save_best_only=True)
history = model.fit(
train_x,train_y,
epochs=epochs,
batch_size=batchSize,
validation_data=(test_x, test_y),
verbose=2,shuffle=False,callbacks=[checkpointer],)
logger.info(model.summary())
show_picture(history, imageFolder)
LSTM模型预测:
模型预测后的得到的结果为[n,1,m]类型,需要重新reshape得到最终的结果
yhat = model.predict(test_X)