数据库读取组件
- 数据多维分析组件总体介绍文档:https://xuelangyun.yuque.com/docs/share/7cc07823-9da6-47b2-b373-247a116afc6d?# 《数据分析组件》
- 输入数据
- 组件支持数字、字符串、JSON三种输入,输入数据会作为变量拼接在自定义SQL语句中。
- 数据库连接界面
- 当首次进去组件页面时,页面会自动弹出一个连接窗口,让用户进行连接设置

- 添加数据库连接,点击左上角"数据库连接"按钮或连接右边的“+”,目前支持MySQL、Postgresql、Hive、SqlServer、Oracle、MariaDB、influxDB共7种数据库源,如下图所示:

- MySQL数据库连接界面,如下图所示:
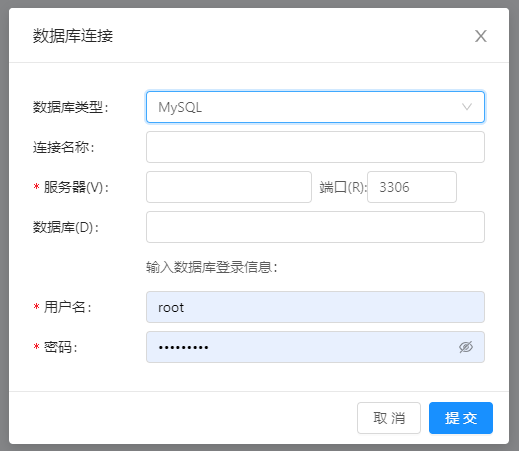
- 服务器:服务器ip或者hostname
- 端口:服务端口,默认为3306
- 数据库名称:需要连接的数据库名称
- 用户名
- 密码
- MariaDB数据库连接界面,与MySQL界面类似,如下图所示:

- Postgresql数据库连接界面,与MySQL界面类似,如下图所示:

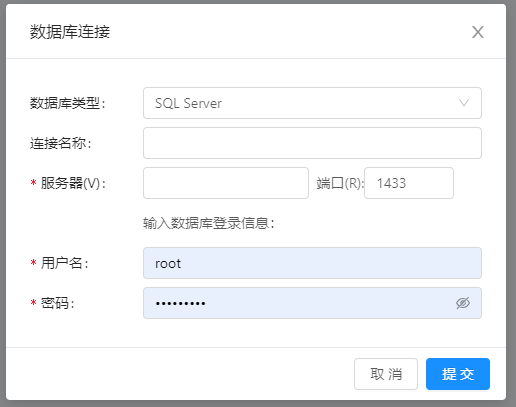
- Sql Server数据库连接界面,与MySQL界面类似,如下图所示:
- Hive数据库连接界面,如下图所示:

- 身份验证:可选无身份验证、kerberos、用户名和密码三种不同的登录方式连接到Hive数据库。
- Oracle数据库连接界面,如下图所示:

- 连接类型:选择不同的连接类型连接到Oracle数据库,可选Basic和TNS。
- InfluxDB数据库连接界面,如下图所示:

- 数据库连接成功后界面

- 左侧上方为数据库连接列表,用户可以点击切换已经创建的连接,右侧列名会相应变化
- 数据库连接可以进行删除、修改操作,如下图所示:

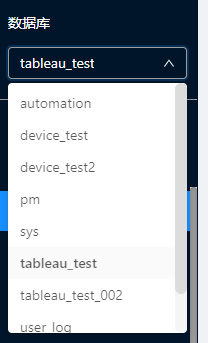
- 左侧中间为数据库名称列表,用户可以选择需要使用的数据库
- 左侧下方栏为该数据库中的表,可以选中相应的表名,获取表中的schema信息以及预览信息(包含前100条数据)

- 选中表后的界面

- 界面的左侧,展示了当前选中表的schema,即列的名称与类型
- 默认所有字段都会被选中,传递到下一个节点中,但也可以勾选所需的列,仅将选中的列传递到下一个节点中
- 界面的右侧,展示了选中表的数据预览,显示选中表的前100条数据
- 数据库设置完成按钮:点击“部署”后,配置完成,节点向下一个节点发送数据,“部署”按钮切换为“编辑”按钮

- 当前状态代表配置已完成,节点开始向下一个节点发送数据

- 当前状态代表配置未完成,节点取消向下一个节点发送数据
- 输出数据格式设置:右上角"设置输出格式"按钮,如下图所示,可以选择输出的格式:
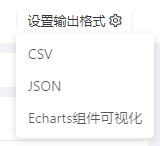
- CSV:输出结构化数据文件
- JSON:形如[{"a": 1, "b": 2}, {"a": 3, "b": 4}]格式的JSON数据
- Echarts组件可视化:形如[["a", "b"], [1, 2], [3, 4]]格式的JSON数据,主要是与算盘的前面板组件对接,进行数据可视化使用
- 自定义SQL功能
- 选择与“字段选择”同级的“SQL查询”标签,进入自定义SQL页面

- 输入自定义SQL后,运行按钮亮起,此时可以执行,点击运行执行自定义SQL语句,右侧显示SQL运行结果预览

- 当把输入变量作为SQL语句中的一部分时,点击运行,会弹出“模拟输入桩数据”弹窗,默认值为组件输入桩输入的值,可以修改本次执行SQL语句时该变量的值,但是仅作测试。点击确认执行带输入变量的SQL语句

- 当设置了自定义的SQL之后,向下一个节点发送的数据就变成了这个SQL执行的结果
- 数据增量读取设置
- 该功能默认关闭
- 当执行SQL查询之后,该功能才可以被开启
- 设置界面如下图所示:

- 设置增量字段,仅支持int类型的字段,根据该字段进行数据增量读取,建议使用类似id的Int型自增字段
- 当前增量进度为之前读取到的数据该列的值,默认为0
- 下一阶段起始值 默认与 当前增量进度 相同,但支持用户手动调整从某个值开始继续读取数据。
- 点击右下“设置”按钮,完成增量读取设置
- 完成增量读取设置后,在“SQL查询”页面下,“增量读取列”和“增量读取行”作为两个新的变量能够拼接在自定义SQL语句中。通过SQL语句中的WHERE条件,可实现增量读取
