模型优化与微调
什么是模型微调
在实践中,由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做特征提取器。
以下是常见的两类迁移学习场景:
1 卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。这样提取的特征叫做CNN codes。得到这样的特征后,可以使用线性分类器(Liner SVM、Softmax等)来分类图像。
2 Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常常只需要Fine-tuning后面的层。
在ImageNet上训练一个网络,即使使用多GPU也要花费很长时间。因此人们通常共享他们预训练好的网络,这样有利于其他人再去使用。例如,Pytorch有预训练好的网络地址Model Zoo。
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:新数据集的大小、以及新数据和原数据集的相似程度。有一点一定记住:网络前几层学到的是通用特征,后面几层学到的是与类别相关的特征。这里有使用的四个场景:
1、新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2、新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
3、新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4、新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
预训练模型的限制。使用预训练模型,受限于其网络架构。例如,你不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小图像;卷积层和池化层对输入数据大小没有要求(只要步长stride fit),其输出大小和属于大小相关;全连接层对输入大小没有要求,输出大小固定。
学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。
案例
要解决的问题
依然使用Cat vs Dog数据集,数据集详情请参考https://www.yuque.com/suanpan_doc/public/dx8z5f。
解决方案
在算盘的项目模板中,已经创建了一个简单的流程可以参考。
在项目模板中,双击keras教材案例中的模型优化与微调:
 建出以下模板,模板中的组件可以在深度学习的pytorch的分类中找到:
建出以下模板,模板中的组件可以在深度学习的pytorch的分类中找到: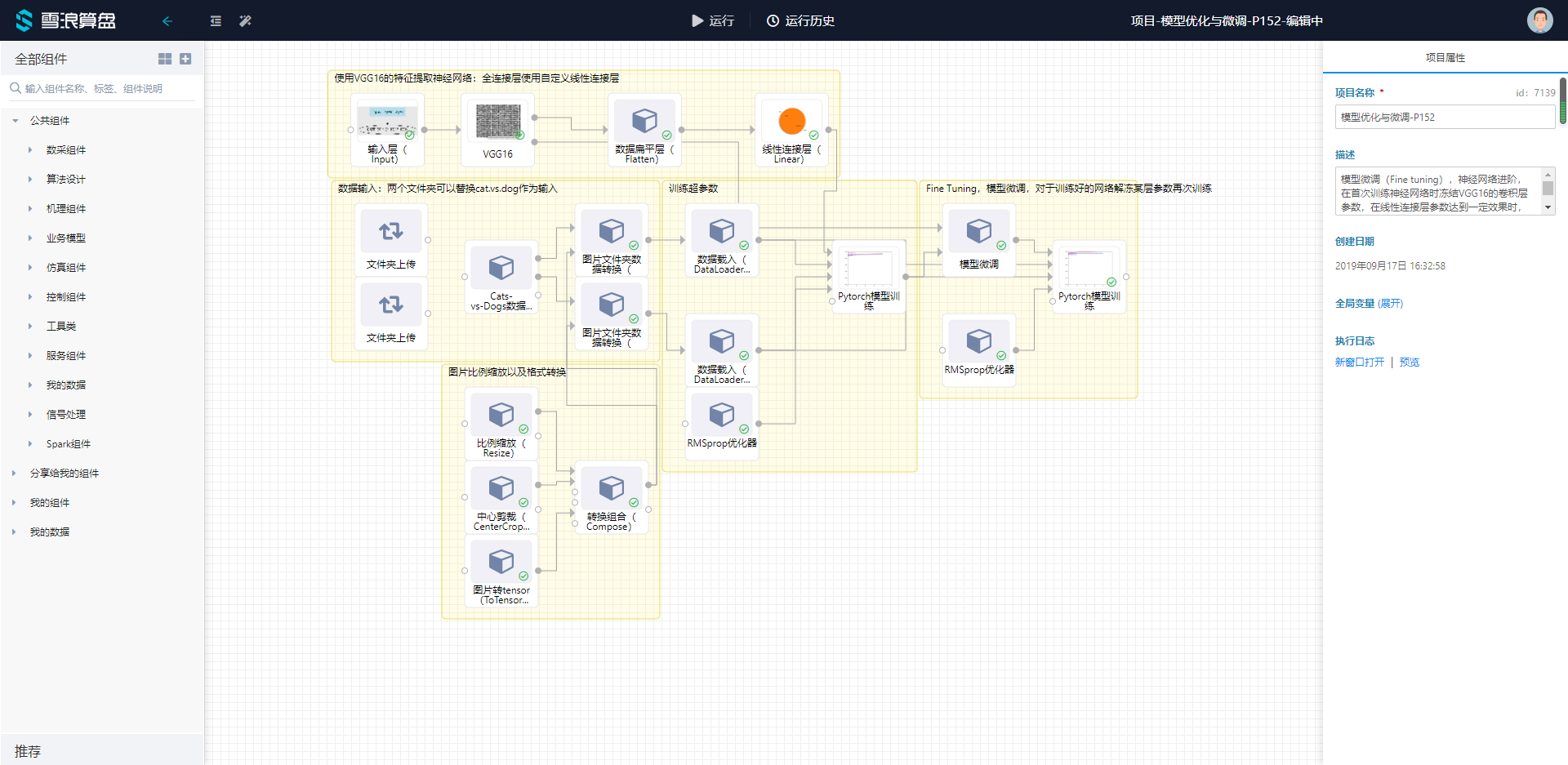
模板
可以看出整个模板分了五块:
- 模型建立——需要有一个输入层,注意填写接收图片的大小与通道数,后面连接VGG16,扁平层以及全连接层。注意预训练模型需要被设置为使用特征提取器,即勾选特征提取器。
- 数据载入——可以使用已经制作好的数据集组件Cats-vs-Dogs数据集组件,组件会直接将数据分为训练集,验证集和测试集,后面可以直接连接图片文件夹数据转换组件。
- 模型训练——数据载入设置Batch Size,选择RMSprop作为参数寻优器,模型训练节点设置epoch数与Loss Function,最终生成训练好的模型文件
- 模型微调——对于未冻结的网络层进行再次训练。
- 图片格式化——由于每张图片的大小不等,需要先将图片比例缩放之后再进行剪裁,案例中将图片变换为1501503的数据格式。
训练过程
- 首先运行到第一个模型训练节点。
- 选择需要解冻的VGG16的网络层,fineTuning参数中选择1个或多个网络层,运行VGG16节点(VGG16单独运行即可)。
- 运行模型微调节点对前面生成的训练好的模型网络层进行冻结或解冻操作,以及运行优化器。
- 最后运行最后的训练节点即可。
结果
两个训练过程结束后,可以观察训练准确率,前一次的最高准确率为92%,模型微调之后为95%,你还可以通过增加训练轮数等操作改进模型。
- 第一次训练

- 第二次训练
 这样就实现了一个神经网络模型微调的过程,你可以对其中的网络结构进行重新编辑,验证你的算法!
这样就实现了一个神经网络模型微调的过程,你可以对其中的网络结构进行重新编辑,验证你的算法!