拉普拉斯映射LE
拉普拉斯映射LE
**1、介绍
拉普拉斯特征映射(Laplacian Eigenmaps)是一种不太常见的降维算法,它看问题的角度和常见的降维算法不太相同,是从局部的角度去构建数据之间的关系。也许这样讲有些抽象,具体来讲,拉普拉斯特征映射是一种基于图的降维算法,它希望相互间有关系的点(在图中相连的点)在降维后的空间中尽可能的靠近,从而在降维后仍能保持原有的数据结构。
2、推导
拉普拉斯特征映射通过构建邻接矩阵为(邻接矩阵定义见这里)的图来重构数据流形的局部结构特征。其主要思想是,如果两个数据实例和很相似,那么和在降维后目标子空间中应该尽量接近。设数据实例的数目为,目标子空间即最终的降维目标的维度为。定义大小的矩阵,其中每一个行向量是数据实例在目标维子空间中的向量表示(即降维后的数据实例)。我们的目的是让相似的数据样例和降维后的目标子空间里仍旧尽量接近,故拉普拉斯特征映射优化的目标函数如下:
下面开始推导:
其中是图的邻接矩阵,对角矩阵是图的度矩阵,成为图的拉普拉斯矩阵。
变换后的拉普拉斯特征映射优化的目标函数如下:
其中限制条件保证优化问题有解,下面用拉格朗日乘子法对目标函数求解:
其中用到了矩阵的迹的求导,具体方法见迹求导。为一个对角矩阵,另外、均为实对称矩阵,其转置与自身相等。对于单独的向量,上式可写为: ,这是一个广义特征值问题。通过求得个最小非零特征值所对应的特征向量,即可达到降维的目的。
关于这里为什么要选择个个最小(PCA选择最大)非零特征值所对应的特征向量,将带回到中,由于有着约束条件的限制,可以得到。即为特征值之和。我们为了目标函数最小化,要选择最小的mm个特征值所对应的特征向量。
3、步骤
使用时算法具体步骤为:
步骤1:构建图
使用某一种方法来将所有的点构建成一个图,例如使用KNN算法,将每个点最近的K个点连上边。K是一个预先设定的值。
步骤2:确定权重
确定点与点之间的权重大小,例如选用热核函数来确定,如果点和点相连,那么它们关系的权重设定为:
步骤3:特征映射
计算拉普拉斯矩阵L的特征向量与特征值:
使用最小的个非零特征值对应的特征向量作为降维后的结果输出。
4、核心代码
KNN算法:
def knn(inX, dataSet, kNeighbour):
"""KNN algorithm.
Arguments:
inX {np.array} -- data of i
dataSet np.array} -- data
k_neighbour {Int} -- the k near number of Knn
Returns:
sortedDistIndicies -- Index of points adjacent to i
"""
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = np.array(diffMat) 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances 0.5
sortedDistIndicies = distances.argsort()
return sortedDistIndicies[0:kNeighbour]
LE算法:
def laplaEigen(data, k_neighbour, t_value):
"""feature function.
Arguments:
data {np.array} -- data
k_neighbour {Int} -- the k near number of Knn
t_value {int} -- w Weights need parameter
Returns:
feature_value -- Eigenvalues.
featur_vector -- Eigenvector.
"""
m = np.shape(data)[0]
W = np.mat(np.zeros([m, m]))
D = np.mat(np.zeros([m, m]))
for i in range(m):
k_index = knn(data[i, :], data, k_neighbour)
for j in range(k_neighbour):
sqDiffVector = data[i, :] - data[k_index[j], :]
sqDiffVector = np.array(sqDiffVector) ** 2
sqDistances = sqDiffVector.sum()
W[i, k_index[j]] = np.math.exp(-sqDistances / t_value)
D[i, i] += W[i, k_index[j]]
L = D - W
X = np.dot(D.I, L)
Calculate eigenvalues and eigenvectors of a matrix
feature_value, feature_vector = np.linalg.eig(X)
return feature_value, feature_vector
5、执行结果
选取KNN临近点个数kNeighbot,W权重的参数点tvalue和降维后的维数dimension.此次测试针对波士顿房价中的14个特征参数进行降维,最后选取最佳的5个特征值作为降维后的数据特征。
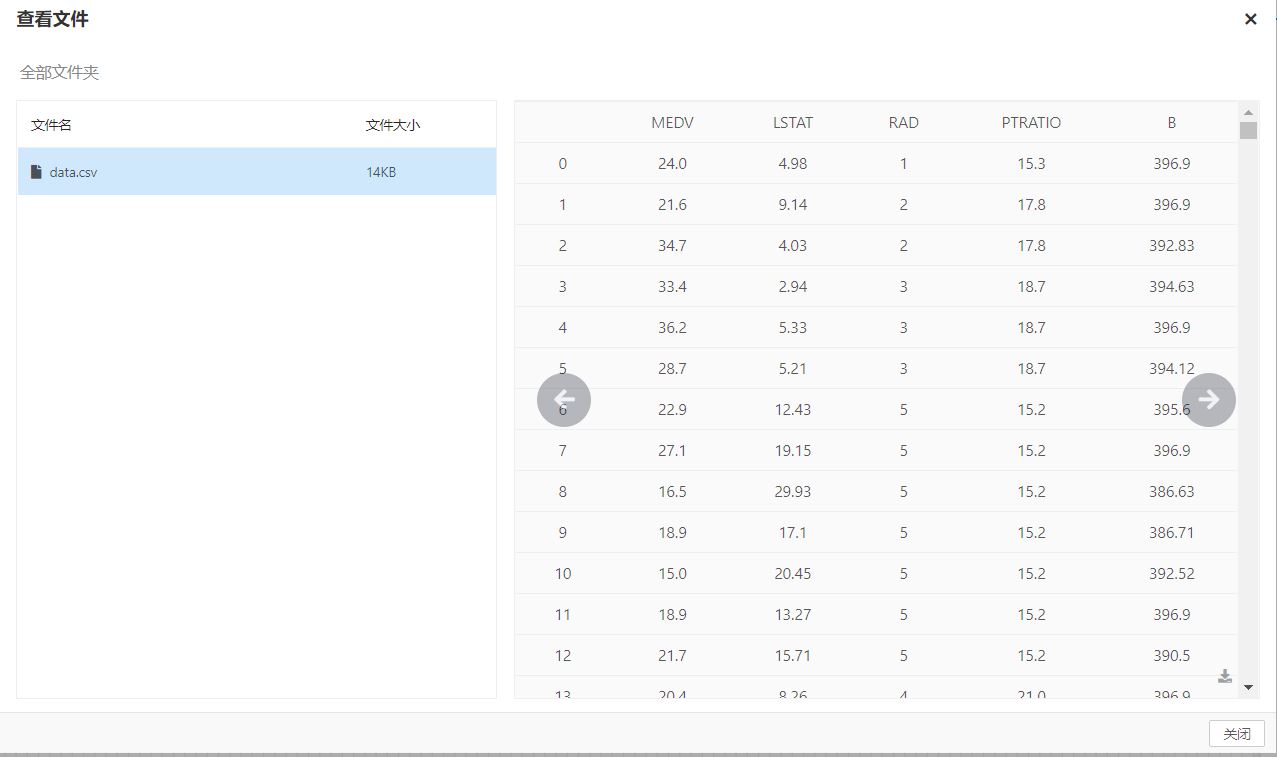 降维后选取的最佳的5个特征值数据集
降维后选取的最佳的5个特征值数据集