高级搜索
1 说明
1.高级检索的设计理念,其实是对常规 sql 查询语法的一种归纳、概括,熟悉 sql 查询语法的用户应该能够很快地上手该元件的配置。
与 sql 查询语法的对照关系如下所示:
| sql | 配置 |
|---|---|
| select sum(t1.field1) as sumNum, t2.field5 |  |
| from t1 |  |
| left join t2 on t2.id = t1.id |  |
| where t1. field3 = 'xxx' and t2. field4 like '%abc%' |  |
| group by t2.field5 |  |
| order by t2.field5 desc |  |
| limit 0,10 |  |
2.配置
主实体&主实体别名
主实体,用于从领域模型中选择一个实体,来当作本次高级搜索的中心实体。
主实体别名,给选择好的实体起一个名字,方便后续在选实体属性的地方,区分这个属性究竟来自哪个实体。

这里以【用户】作为主实体。
关联实体
可以为本次查询,添加关联实体,前提是该关联实体与前面已选择的实体之间有关联关系。

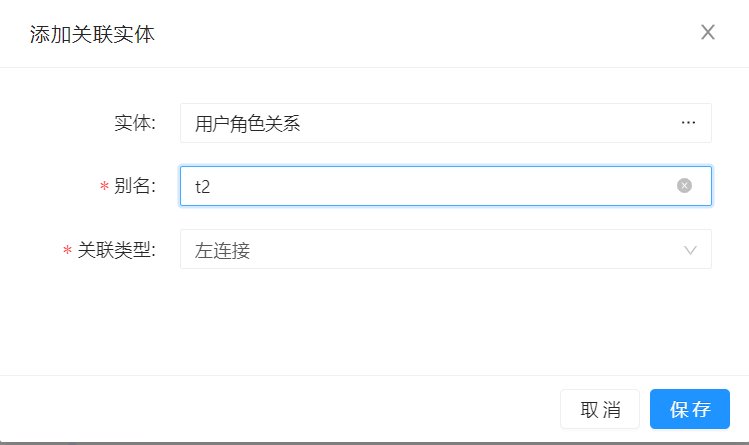
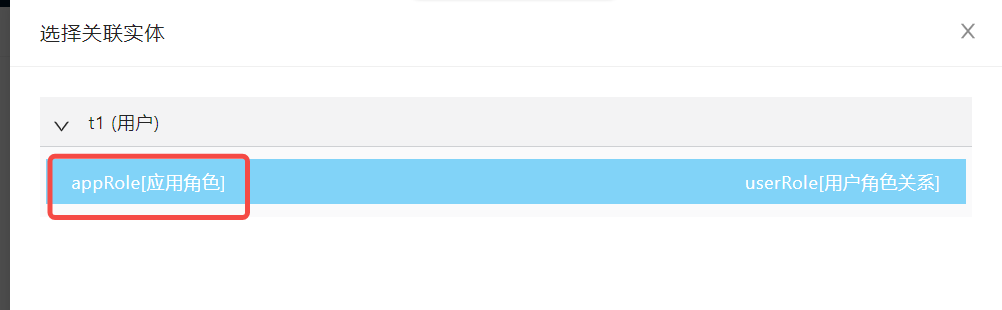
这里以【应用角色】作为关联实体,使用的是【用户角色关系】关联关系。
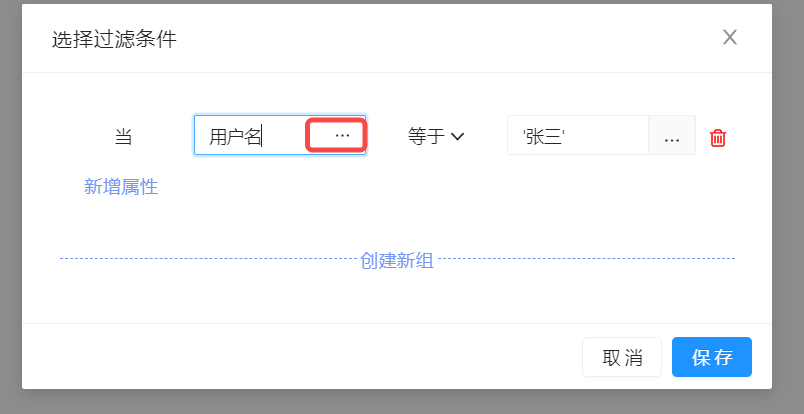
过滤条件
可以根据上面所有已经选择好的主实体、关联实体,针对它们的实体属性,来添加过滤条件,即对数据进行筛选。


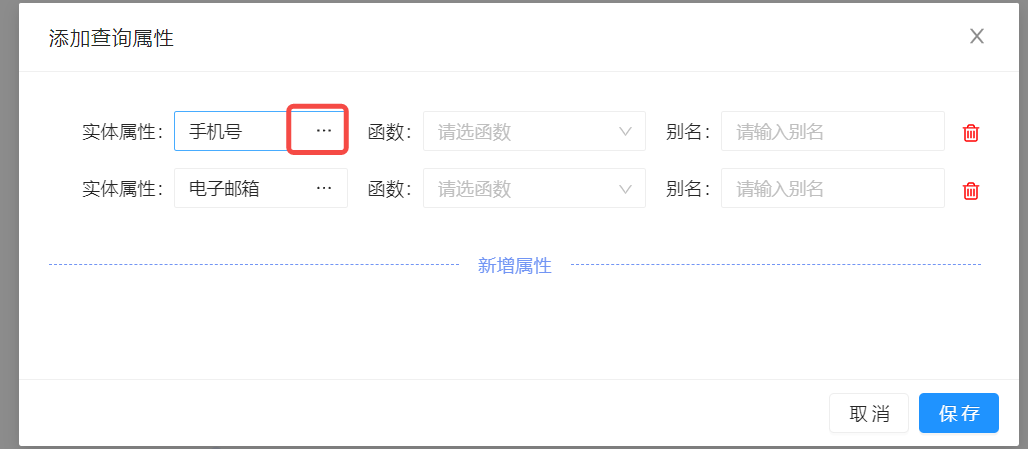
查询
因为上面已经选择好了主实体,关联实体,但是我们有时候不希望获取到它们所有的属性,这个时候,就可以选择我们需要的属性来获取,即作为查询属性。

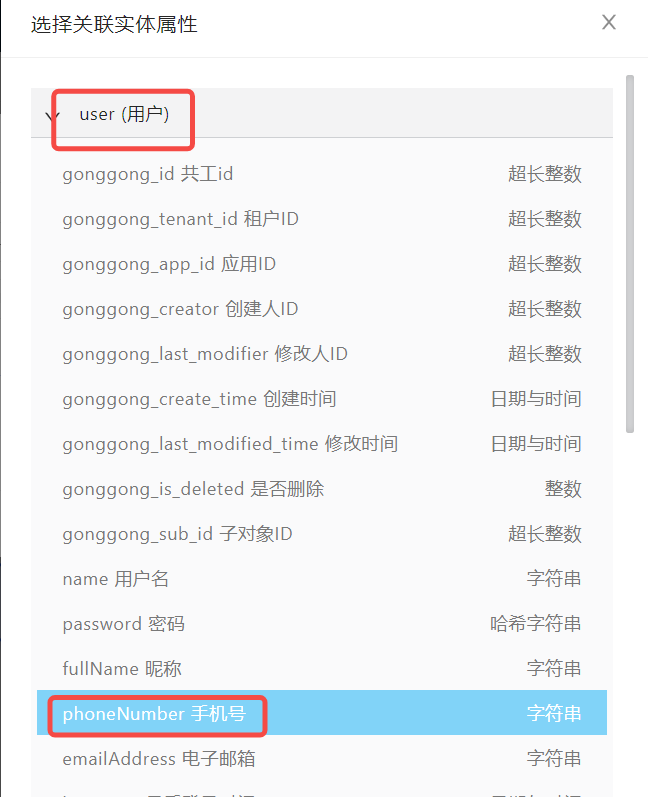
函数

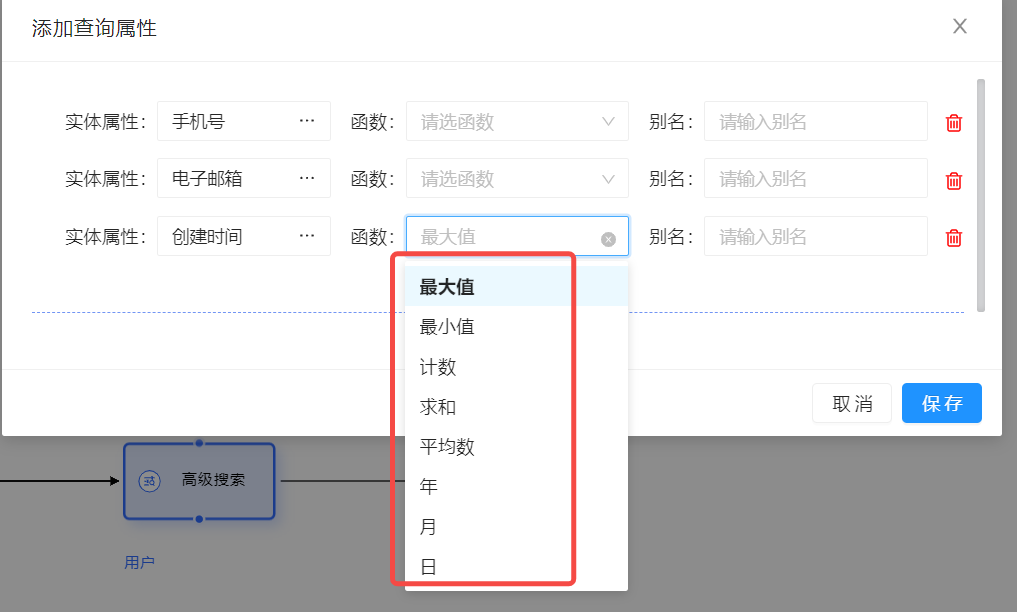
函数表示对该属性做一些计算,然后再返回数据,支持的函数如下:
| 函数 | 说明 |
|---|---|
| 最大值 | 可以单独使用,也可以配合分组使用,用于计算当前全量数据、分组数据中,该属性的最大值。 |
| 最小值 | 可以单独使用,也可以配合分组使用,用于计算当前全量数据、分组数据中,该属性的最小值。 |
| 计数 | 可以单独使用,也可以配合分组使用,用于计算当前全量数据、分组数据中,该属性的行数。 |
| 求和 | 可以单独使用,也可以配合分组使用,用于计算当前全量数据、分组数据中,该属性的累加值,该属性必须是数字类型。 |
| 平均数 | 可以单独使用,也可以配合分组使用,用于计算当前全量数据、分组数据中,该属性的平均数,该属性必须是数字类型。 |
| 年 | 返回当前属性代表的年份,当前属性必须是日期时间类型 |
| 月 | 返回当前属性代表的月份,当前属性必须是日期时间类型 |
| 日 | 返回当前属性在一年中代表的天数,当前属性必须是日期时间类型 |
分组
分组,会根据上述过滤条件查询出来的数据,按照分组属性,把具有相同分组属性值的数据,归为一组。
一般在对数据需要做一些统计工作时,会用到分组,且分组通常会配合聚合函数使用,聚合函数在查询的函数中会有体现。


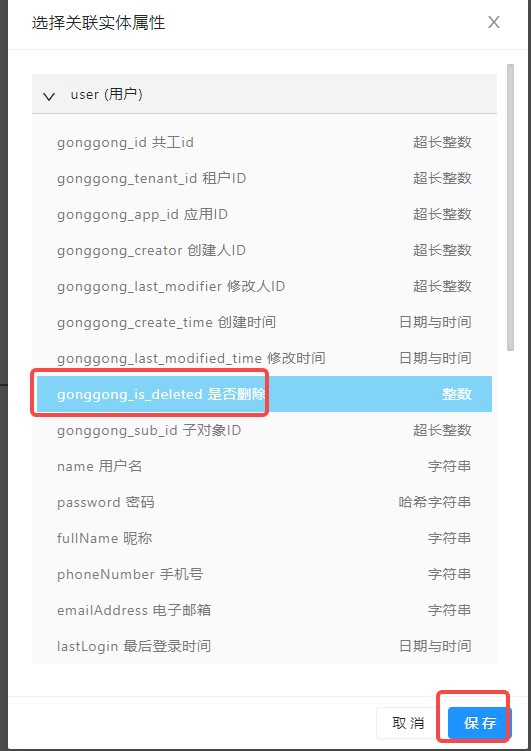
上述配置就会根据用户表的是否删除字段,做分组。从通常业务上来看,一般会分为两组数据,一组是已删除数据,一组是未删除数据。
排序
用于对根据上述过滤条件、分组条件查询出来的数据做排序,可以根据不同的排序属性以及排序类型做排序。



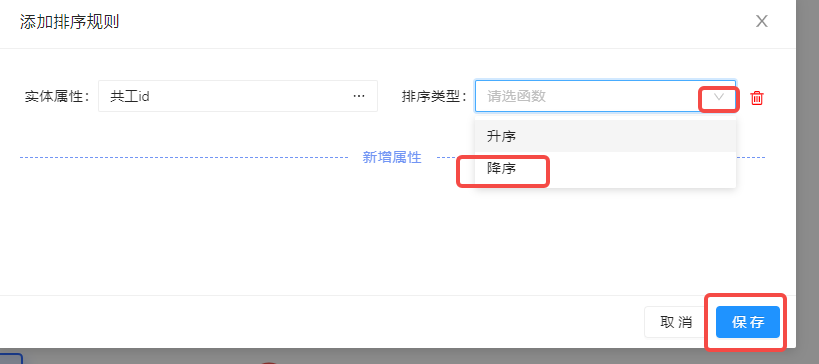
上述配置就会根据用户表的共工 id 做降序排序。
范围
范围一般是用于做分页需求。
比如前端需要第一页的数据,前端会传页码=1,数据条数=10 到后端。
这个时候,就需要在该配置项中的跳过记录数填 0,在返回记录数中填 10。
具体的公式如下:
跳过记录数 = (页码 - 1) * 数据条数
返回记录数 = 数据条数

是否去重
如果您发现最后查询出来的数据,有重复的情况,就可以使用该配置。
该配置项打开,就会对查询出来的数据做去除重复行的操作。

分页依据
如果该元件查询出来的总条数是用于前端分页的准确依据,则可以打开该配置。
一般而言,一条逻辑中,只会有一个元件打开该配置项。
该配置项通常与范围一起使用。
返回类型
用于表明上述查询出来的数据,将映射成何种数据类型。


实体
当返回类型选择实体或者实体集合时,需要额外指明具体的实体类型。

变量名称
用于表明,在把对该查询返回数据的使用权放置到执行流中去后,后续元件如何精准使用到该数据,即给该数据起个名字。